
Mipsology Zebra on Xilinx FPGA Beats GPUs, ASICs for ML Inference Efficiency
November 16, 2020
Blog

Results Highlight “Zero Effort” Architecture Benefits for Computing Neural Networks.
Mipsology announced that its Zebra AI inference accelerator achieved the highest efficiency based on the latest MLPerf inference benchmarking. Per the company, the Zebra on a Xilinx Alveo U250 accelerator card achieved more than 2x higher peak performance efficiency compared to all other commercial accelerators.
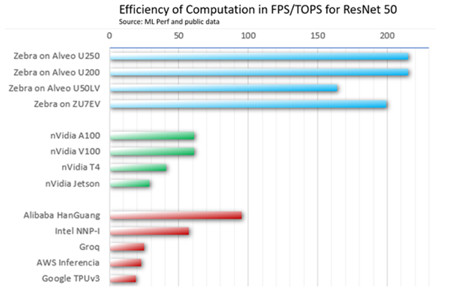
Efficiency of Computation (source: MLPerf and Internet data)
Peak TOPS have been the standard for measuring computation performance potential, many assume that more TOPS equal higher performance. However, this fails to take into consideration the real efficiency of the architecture, and the fact that at some point there are diminishing returns. This achievement, similar to “dark silicon” for power, occurs when the circuitry can not be used because of existing limitations. Zebra has proven to scale along with TOPS, maintaining the same high efficiency while peak TOPS are growing.
With a peak TOPS of 38.3 announced by Xilinx, the Zebra-powered Alveo U250 accelerator card outperformed competitors in terms of throughput per TOPS and ranks among the best accelerators available today. It delivers performance similar to an NVIDIA T4, based on the MLPerf v0.7 inference results, while it has 3.5x less TOPS. In other words, Zebra on the same number of TOPS as a GPU would deliver 3.5x more throughput or 6.5x higher than a TPU v3.
This performance does not come at the cost of changing the neural network. Zebra was accepted in the closed category of MLPerf, requiring no neural network changes, high accuracy, and no pruning or other methods requiring user intervention. Zebra achieves this efficiency all while maintaining TensorFlow and Pytorch framework programmability.
MLPerf has been the industry benchmark for comparing the training performance of ML hardware, software and services since 2018, and inference performance since 2019.
For more information, visit: www.mipsology.com



