
The Invention of Apple's Siri and Other Virtual Assistants
October 29, 2020
Blog

Many of our electronic devices are now able to listen in on, or even participate in, human conversations. Speech processing provides the foundation for these interactions today.
Many of our electronic devices are now able to listen in on, or even participate in, human conversations. Speech processing provides the foundation for these interactions today, but has been around much longer than you might think.
1950s: Speech Processing
Research and development around computer systems that can understand phonics has been underway since 1952. Originally focused on numbers instead of words, Bell Labs created the Automatic Digit Recognition machine called “Audrey” that was able to understand basic speech sounds known as phonemes, as well as single digits (0 to 9), spoken aloud by one voice.
Almost 70 years ago, Audrey was able to detect basic phonemes and numbers with up to 90% accuracy, but because the system was only able to understand numbers its application was limited to voice dialing for collectors and toll operators.

IBM took the next step towards speech recognition at the 1962 Seattle World’s fair where they debuted their “Shoebox’ machine that was able to understand and respond to 16 words in English. The machine was also able to understand mathematical functions and understand digits, much like the machine that came before it. Later, the Shoebox evolved to be able to comprehend nine consonants and four vowels.
1960s: Speech Recognition
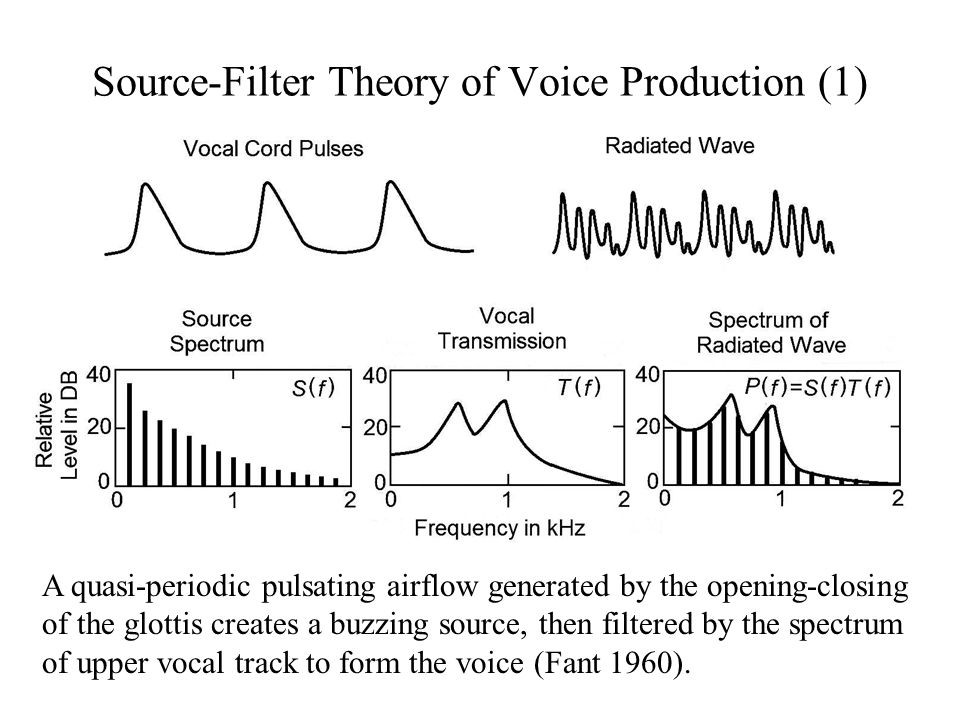
The 1960s seemed to be fundamental to the development of speech recognition systems as the decade coincided with the advent of more advanced signal processing hardware that could be used to understand both speech and sound. Along with advances at Bell Labs and IBM, speech science researcher Gunnar Fant founded the Source-Filter model of speech production. Fant’s model analyzed the source from where we produce speech sounds, as well as the way we filter those sounds, which for humans is the vocal tract or vocal folds that vibrate when we produce sound. For Fant, and the development of speech processing as a whole, it was important to understand HOW humans created sound before making a system that could mimic it.
1970s: Speech Understanding
The 1970s delivered a breakthrough in voice recognition technology after DARPA and the U.S. Department of Defense created the government funded Speech Understanding Research program (SUR). The goal of SUR was to create a system that would be able to comprehend at least 1,000 words, and various companies and universities, including Carnegie Mellon University, joined the program to eventually create the “Harpy” speech system. Harpy was capable of understanding full sentences, and eventually understood 1,011 words – the equivalent of a three-year-old’s vocabulary.

1980s: Statistical Models for Speech Recognition
Both IBM and Bell Labs re-entered the scene in the 1980s after the hidden Markov model (HMM) statistical model was introduced, which allowed systems to estimate the probability of unknown sounds actually being words.
These advancements led to the creation of the first speech recognition company, Threshold Technology. Bell Labs’ speech recognition systems were also able to understand multiple voices by this time, and IBM’s “Tangora” voice-activated typewriter maintained a 20,000 word vocabulary.
1990s: Continuous Voice Processing
The 90’s were a time for faster microprocessing speeds, allowing software companies such as Dragon Systems to develop comprehensive speech recognition systems like Dragon Dictate, released in 1990. Dragon Dictate utilized HMMs, which were not yet compatible with many of the hardware platforms available at the time, and struggled to understand continuous chains of words. This meant users had to enunciate and pause between each word, making it hard to justify the $9,000 initial price point.
However, Dragon continued refining their products and released Dragon NaturallySpeaking in 1997, which became the first continuous speech recognition system to understand 100 words per minute. Users also didn’t have to pause between words.

In 1996, BellSouth created the first voice activated portal (VAL), an interactive voice recognition system for dial-in customers. The system from BellSouth was geared towards providing services over the phone, much like the automated voice menus we have today.
2000s: Voice Recognition for Virtual Assistants
By 2001, advanced speech recognition software was routinely achieving 80% accuracy, and companies like Google began capitalizing on this performance via the Google Voice Search app. The Google Voice Search app and search engine captured and offloaded roughly 230 billion words from user searches to Google data centers that would later be used to predict what users were searching for and help advance the development of speech processing technology.
Not only was this a breakthrough in speech processing, but also signaled the beginnings of smart consumer devices: Apple’s iPhone and Google Android both featured voice recognition capabilities just a few years later.
Apple launched their own virtual assistant software, Siri, in 2011. Siri was one of the first voice recognition systems able to converse back and forth with the user, allowing it to double as one of the first AI-based virtual assistants. Microsoft followed Google and Apple with the Cortana virtual assistant in 2014, which proliferated to various Windows-based platforms and the Xbox One.

The evolution of speech processing is often compared to a child growing up and learning new words while also forming their sense of personality. As the technology continues to advance, we can expect better accuracy, a more advanced, diverse vocabulary, and more human-like interactions with devices all around us that can literally speak the same language.



