
Smart architectures bring AI to mobile devices
May 19, 2015

Deep learning algorithms are being used to train convolution neural networks (CNN) to enable smarter mobile devices and this may well require a new ap...
Deep learning algorithms are being used to train convolution neural networks (CNN) to enable smarter mobile devices and this may well require a new approach to processing architectures. But in the meantime, smartly leveraging current technologies may help get us further down the path to truly cognitive devices capable of completely redefining the user experience.
It was telling that Nvidia would use the automobile and advanced driver-assistance systems (ADAS) as a focal point for applications at its GPU Tech Conference in March, complete with a discussion and comments from Elon Musk to indicate that self-driving cars are almost a solved problem. However, with time, and some tweaks and refinements – with an eye toward ultra-low power consumption – I see many of the technologies and applications, from ubiquitous 3D sensing, 3D tracking, and even visual search, moving quickly into smartphones and both powered and battery-driven embedded systems.
Coupled with sensors for movement and audio, fast memory access, and a power-efficient approach to data processing, these systems can be truly “cognitive” and may even form a platform for artificial intelligence-enabled mobile devices in the not-too-distant future. In the meantime, it’s important to optimize current architectures to enable “intelligent vision” features, like 3D depth mapping and perception, object recognition, and augmented reality, along with core computational photography features such as zoom, HDR, image refocus, and low-light image enhancement.
These latter functions are blurring the distinction between computer vision and image processing as many of the imaging and image-enhancement functions use computer vision techniques. The easiest example of this is multi-frame image-enhancement functions, like HDR, zoom and refocus, where you take multiple consecutive images and then fuse them together to get a higher quality image.
While we call this “image enhancement,” there’s a lot of computer vision involved to “register” the image, which involves matching two or three frames to each other. That basic functionality is taken for granted now, but requires a lot of processing horsepower. And this requirement for focused, intensive digital signal processing (DSP) will only increase.
Qualcomm did a good job plotting the pixel power and time relationship for various vision processing functions in a paper presented at Uplinq 2013. As shown in the figure, the plots were based on three processors: a single-core CPU running at 1.2 GHz, a quad-core CPU, and a DSP running at 690 MHz.
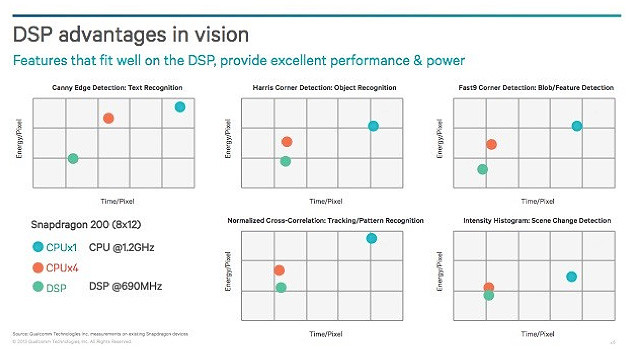
Figure 1: Plotting energy per pixel against time per pixel for various processors shows the advantages of a DSP to accompany the CPU for vision processing. To optimize for power and functionality, the combination of CPU, DSP, and GPU may be the best overall approach. (Click to zoom)
The plot shows that a DSP running at just over half the CPU’s clock frequency can achieve the same results on an image, giving potential gains in performance, while providing further savings in power (power = capacitance x voltage2 x frequency, or P=CV2xF).
However, as we move toward performing human-like vision, AI, and augmented-reality applications on mobile platforms, a rethink of the processing architectures may be required. Combining sensor fusion and advanced deep-learning algorithms such as CNN, these highly advanced and mathematically intensive applications will provide a more ambient- and context-aware user experience, but will force a trade-off in terms of battery life.
The challenge for designers is to enable this new world of cognitive devices while maintaining acceptable battery life. There are a few ways to achieve this. For example, the CPU could be supported by a GPU from Qualcomm or Nvidia. This is already being implemented in many smartphones. However, the uncompromising need for ever-lower power consumption suggests that specific processing-intensive functions could be allocated to a vision-optimized DSP core. Taking this approach can give up to power consumption 9X improvement verses today’s advanced GPU cluster, while running object recognition and tracking.
Even with this level of power savings, it’s unlikely that mobile devices will be performing crowd searching using facial recognition any time soon because it’s too processing intensive. But the availability of low-power processing cores and optimized architectures has increased optimism and solid progress is being made. Such progress was one of the reasons MIT Technology Review called out deep learning as one of the 10 technology breakthroughs of 2013. And was demonstrated at GTC and presented in other research from the likes of Microsoft, Baidu, and Cognivue, much has happened since then.
In addition, Aziana (Australia) recently announced it was merging with BrainChip (California), a company dedicated to realizing artificial intelligence in hardware and which has now set its sights on AI for mobile platforms.
While processing architectures and low-power processing are critical, it’s fair to assume that as cloud connections become more ubiquitous and faster, we should assign as much processing overhead to the cloud as possible. Again, it comes down to smart partitioning. Do in the cloud what’s best to do in the cloud and then on the mobile device, architect functional allocation as efficiently as possible, such as using the CPU to distribute the load between the GPU and DSP. Or as Qualcomm puts it, take advantage of the right engine for the right task.
Eran Briman serves as a vice president at CEVA. Previously, as Chief Architect, he had overall responsibility for the research and development of next generation DSP Cores. Briman holds a BS in Electronic Engineering from Tel-Aviv University and an MBA from the Kellogg Business School in Northwestern University and holds several patents on DSP technology.




