
Artificial Neural Networks (ANN) on Snapdragon-based Edge Devices
September 24, 2018
Product

Qualcomm Snapdragon Platforms and the Qualcomm Snapdragon Neural Processing Engine software development kit is an outstanding choice to create a customized neural network on low-power devices.
Introduction
Using Artificial Neural Network (ANN) on machines, to make them reach similar capabilities to what the human brain can do is a popular topic and can be seen in different fields. Besides finding the best NN (Neural Network) and training database, another challenge is to implement it on embedded devices while optimizing performance and power efficiency. Using cloud computing is not always an option, especially when the device doesn’t have connectivity. In that case, we need a platform that could do signal pre-processing and execute NN in real-time, with the lowest power consumption possible, especially when a device operates on a battery.
In previous blogs, which can be found on www.intrinsyc.com, we went through a few examples on how to use Qualcomm Snapdragon Platforms for NN use cases. We saw that by using different tools (like python scripts), we can train a network with databases (in Caffe and Tensorflow) formats and then use the Qualcomm Snapdragon Neural Processing Engine (NPE) software development kit (SDK) to convert that network to Snapdragon platforms.
Overview
Qualcomm Snapdragon Platforms and the Qualcomm Snapdragon Neural Processing Engine (NPE) software development kit (SDK) is an outstanding choice to create a customized neural network on low-power and small-footprint devices. The Snapdragon NPE was created to give developers the tools to easily migrate intelligence from the cloud to edge devices.
The Snapdragon NPE provides developers with software tools to accelerate deep neural network workloads on mobile and other edge Internet of Things (IoT) devices powered by Snapdragon processors. Developers can choose the optimal Snapdragon core for the desired user experience – Qualcomm Kryo CPU, Qualcomm Adreno GPU or Qualcomm Hexagon DSP.
In this article, we explore developing and implementing NN on Snapdragon platforms using Matlab tools, and mainly focus on the ONNX format. Also, we investigate how Snapdragon platforms can help us to reduce power and processing time, by using the optimal Snapdragon core, and tools that are provided by the SNPE SDK.
Design and Develop Simple DNN
We start by going through steps on designing and training a Deep Neural Network (DNN), using Matlab and port that design for Snapdragon and look for the best subsystem on Snapdragon to do the job.
Handwritten Digit Recognition System
Let’s start with the handwritten digit recognition system using DNN. One of the major differences between this network and the (Audio Digit Recognition System) is that this system doesn’t have any pre-processing on input signal. Snapdragon platforms, with their heterogenous computing architecture, have powerful engines for audio and image processing using Digital Signal Processors (DSPs) and Graphics Processing Units (GPU).
For developing and training part of this network we use Matlab. This network is a three-layer convolution-based network. We also use the handwritten digits database that comes with Matlab (it is the same as MNIST database; for the source of that database, please check Matlab documentation).
So, let's check the script
- Here we select database
[XTrain,YTrain] = digitTrain4DArrayData;
[XValidation,YValidation] = digitTest4DArrayData;
- Now setting the layers
layers = [ imageInputLayer([28 28 1],'Name','input', 'Normalization', 'none')
convolution2dLayer(5,16,'Padding','same','Name','conv_1')
batchNormalizationLayer('Name','BN_1')
reluLayer('Name','relu_1')
convolution2dLayer(3,32,'Padding','same','Name','conv_2')
batchNormalizationLayer('Name','BN_2')
reluLayer('Name','relu_2')
fullyConnectedLayer(10,'Name','fc')
softmaxLayer('Name','softmax')
classificationLayer('Name','classOutput')];
- and create the network
options = trainingOptions('sgdm',...
'MaxEpochs',6,...
'Shuffle','every-epoch',...
'ValidationData',{XValidation,YValidation},...
'ValidationFrequency',20,...
'Verbose',false,...
'Plots','training-progress');
- And train it (for detail on the training process, please check Matlab documentation)
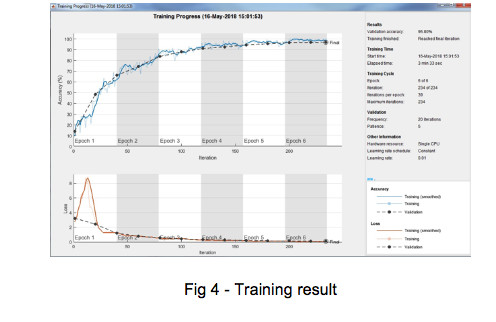
To verify the network, we use this image for the classifier, and as you can see, the network can classify it correctly.
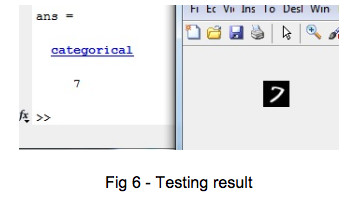
Now after converting the network to ONNX format, we move to the next step, which is using the SNPE tools.
First, we need to convert the ONNX format to DLC.
snpe-onnx-to-dlc -m handwritten-onnx --debug
This will create a DLC format network that can be used for SNPE.
Then using this command, you can verify if the network structure matches with what we created in Matlab.
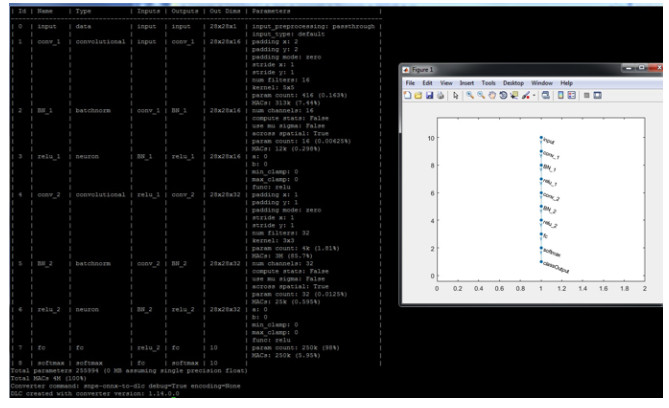
Now we use the same testing images and verify it on the Snapdragon target. Here are the results summary for ARM, cDSP and GPU, using these steps:
- Pull the result of snpe-net-run on platform for different cores (--use_dsp and use_gpu)
- Run snpe-diagview on host machine against the pulled result
|
ARM |
GPU |
DSP |
|
Dnn Runtime Load/Deserialize/Create Statistics: -------------------------------------------------- Load: 4627 us Deserialize: 5148 us Create: 126428 us
Average SNPE Statistics: ------------------------------ Total Inference Time: 10956 us Forward Propagate Time: 3080 us
Layer Times: --------------- 0: 1 us 1: 1298 us 2: 74 us 3: 8 us 4: 908 us 5: 257 us 6: 16 us 7: 465 us 8: 6 us
|
Dnn Runtime Load/Deserialize/Create Statistics: -------------------------------------------------- Load: 4099 us Deserialize: 4931 us Create: 1136097 us
Average SNPE Statistics: ------------------------------ Total Inference Time: 3723 us Forward Propagate Time: 3648 us
Layer Times: --------------- 0: 5 us 1: 31 us 4: 83 us 7: 381 us 8: 5 us
|
Dnn Runtime Load/Deserialize/Create Statistics: -------------------------------------------------- Load: 27535 us Deserialize: 8821 us Create: 246007 us
Average SNPE Statistics: ------------------------------ Total Inference Time: 3837 us Forward Propagate Time: 3795 us
Layer Times: --------------- 0: 29 us 1: 246 us 2: 594 us 3: 9 us 4: 124 us 5: 1056 us 6: 6 us 7: 357 us 8: 30 us
|
Comparing results, shows that DSP and GPU are close, but on these platforms:
- cDSP has no load compared to the GPU (especially if there is a graphical application running).
Using Subsystems for Signal Pre-processing
So far, the DNN network that we have implemented doesn’t need any pre-processing on input signal (like feature extraction from input images). However, this is not the case for all implementations.
For those situations and to achieve lower power consumption, we can use different subsystems on Snapdragon - aDSP, mDSP, cDSP, GPU, DSP/HVX, ARM/NEON. Let’s look at xDSP and examples on how we can use those processors for feature extracting.
Hexagon xDSP on Snapdragon
Hexagon DSP is a multi-thread DSP with L1/2 cache and memory management unit and on most Snapdragon SOCs, it has the same access to a few resources as other cores have. This unique structure besides QuRT OS creates a flexible DSP platform to create applications for different use cases.
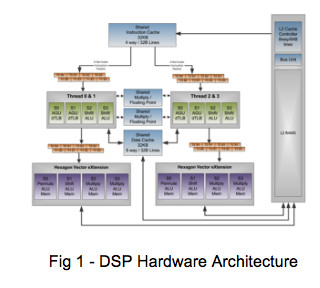
Image Processing
For real-time image processing, you can inject a customized HVX module in the ISP pipeline. The location in the pipeline for this module can be different and it depends on the Snapdragon series. In some platforms, you can have it after the camera sensor interface module.
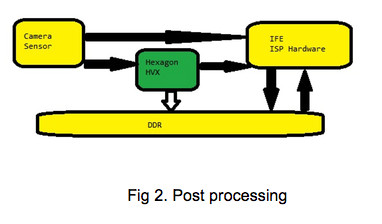
Or in others you can inject the HVX module in a different location of the camera pipeline (red dots).
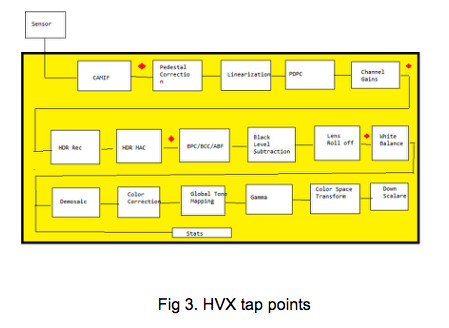
Or it can be used for memory-to-memory transferring after the ISP. There are a few examples that are available in Hexagon SDK 3.3.
As an example, a Sobel processing on a noisy 640x480 image using HVX, can take around 10K PCycles.

Audio Processing
For audio preprocessing, aDSP and its Elite framework is suitable to do feature extraction in real-time. On DNN network for digit recognition system, the input of the network will be Mel-frequency cepstral coefficients (MFCC), using one-second audio files and 14 coefficients, the input layer will be 14x98. The database is collected from https://aiyprojects.withgoogle.com/open_speech_recording and using 1500 audio file for each digit (0-9). Here is an example of MFCC for digit one.
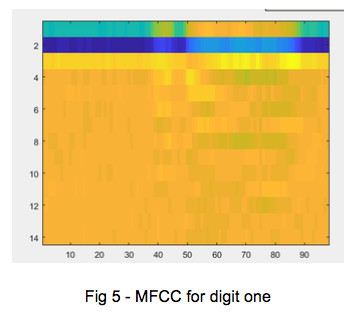
The network is configured as

DNN will try to learn and classify these types of images for different digits. The feature extraction part is done in aDSP as a customized module in audio path topology in Elite framework.
|
ARM
|
GPU
|
DSP
|
|
DNN Runtime Load/Deserialize/Create Statistics:
--------------------------------------------------
Load: 2532 us
Deserialize: 1196 us
Create: 122546 us
Average SNPE Statistics:
------------------------------
Total Inference Time: 9020 us
Forward Propagate Time: 3712 us
Layer Times:
---------------
0: 2 us
1: 1441 us
2: 117 us
3: 18 us
4: 1736 us
5: 86 us
6: 166 us
7: 91 us
8: 4 us
|
DNN Runtime Load/Deserialize/Create Statistics:
--------------------------------------------------
Load: 1729 us
Deserialize: 1168 us
Create: 1137250 us
Average SNPE Statistics:
------------------------------
Total Inference Time: 3429 us
Forward Propagate Time: 3382 us
Layer Times:
---------------
0: 5 us
1: 132 us
4: 209 us
7: 211 us
8: 4 us
|
DNN Runtime Load/Deserialize/Create Statistics:
--------------------------------------------------
Load: 15103 us
Deserialize: 7678 us
Create: 216279 us
Average SNPE Statistics:
------------------------------
Total Inference Time: 4289 us
Forward Propagate Time: 4244 us
Layer Times:
---------------
0: 38 us
1: 263 us
2: 1527 us
3: 9 us
4: 154 us
5: 609 us
6: 5 us
7: 128 us
8: 29 us
|
Sensor Processing
Snapdragon platforms contain a sensor hub, the Snapdragon Sensor Core, that helps to integrate data from different sensors and process them. This technology can help off-load these tasks from the central processor, reducing battery consumption, while also providing improved performance. The pre-processing of any sensor information for any DNN that is targeted for sensor behavior recognition can be off-loaded to the DSP and can be done in real-time.
In all above cases, instead of using assigned DSP for input, you can offload processing from ARM to any other subsystem (like mDSP), using FastRPC, but this technique has its own processing overhead.
Summary
Qualcomm Snapdragon Platforms and the Qualcomm Snapdragon Neural Processing Engine (NPE) software development kit (SDK) provide powerful platforms and tools to create a customized artificial neural network on low-power and small-footprint edge devices.



