
Basic principles of voice UI
October 20, 2017
Story

The efficacy of a voice recognition system depends on a microphone array and collection of algorithms that allows the array to focus on the user?s voice and reject unwanted noises.
Voice user interface (voice UI) features found in the Amazon Echo and Google Home have captured consumers’ attention. Much of the efficacy of a voice recognition system depends on a microphone array and collection of algorithms that allows the array to focus on the user’s voice and reject unwanted noises. The following explains the basic functions of these algorithms.
Trigger/wake word
A voice UI system uses an assigned trigger word (such as “Alexa” or “OK Google”) to activate the voice UI device. The device must do the recognition immediately using its own algorithm, as using Internet resources would create too much delay.
The trigger word must produce a distinctive waveform that the algorithm can distinguish from normal speech, otherwise the percentage of successful recognition may be unacceptably low. Typically, a trigger word using three-to-five syllables is best.
Small trigger word algorithms take less memory and processing but make more mistakes, while large algorithms require more resources but make fewer mistakes. Models are also tunable – they can be stricter (fewer false alarms but more difficult to trigger) or more lenient (more false alarms but easier to trigger). Most product designers choose stricter tunings because customers are unforgiving of false triggers.
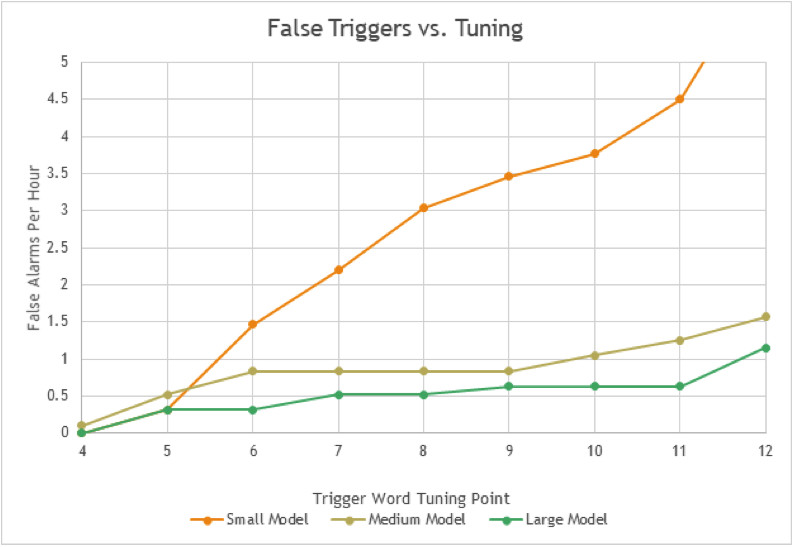
Figure 1 compares the performance of a three-trigger model for different tuning points. Achieving fewer than two false triggers per hour under the test conditions is a reasonable goal. The small model is able to achieve this only with the two strictest tunings on the far left side of the graph. The medium and large models achieve this goal over a wider operating range.

DOA (direction of arrival)
Once the trigger word has been recognized, the next step is to determine the direction of arrival (DOA) of the user’s voice. Once the direction is determined, the DOA algorithm tells the beamformer algorithm in which direction it should focus.
The core function of the DOA algorithm is to examine the phase relationship of the signals coming from the different microphones in the array, and use this information to determine which microphone received the sound first. However, because of reflections from walls, floor, ceiling and other objects in the room, the sound of the user’s voice will also be arriving from other directions. To this end, a DOA algorithm includes precedence logic, which separates the louder initial arrival from the quieter reflections.
The DOA algorithm’s operation is enhanced by automatically adjusting for the ambient noise level. The algorithm measures average noise level in the room, and will only recalculate the position of the user’s mouth if the incoming signal is at least a certain number of decibels above the level of the ambient noise.
AEC (acoustic echo canceller)
To focus better on the user’s voice, a voice UI device must subtract the sounds its own speaker produces from the sounds picked up by its mics. This may seem as simple as blending a phase-reversed version of the program material into the signals coming from the microphones. However, this process is inadequate for dealing with the alterations to the waveform by the speaker, digital signal processing (DSP) equalization, the microphones, and acoustical reflections.
Step one in an AEC algorithm is to compare the outputs of the microphones with the original (pre-DSP) input signal and calculate correction curves to subtract the direct sound from the speaker from the waveform of the voice command.
Step two is subtracting acoustical echoes. The algorithm must “look for” sounds that match the program material within a certain margin of error (to compensate for changes to the waveform caused by acoustics), as well as over a defined time window that corresponds to expected reverberation time. Because each microphone receives a slightly different set of echoes and a different direct sound from the speaker, achieving maximum performance requires separate AEC processing for each microphone.
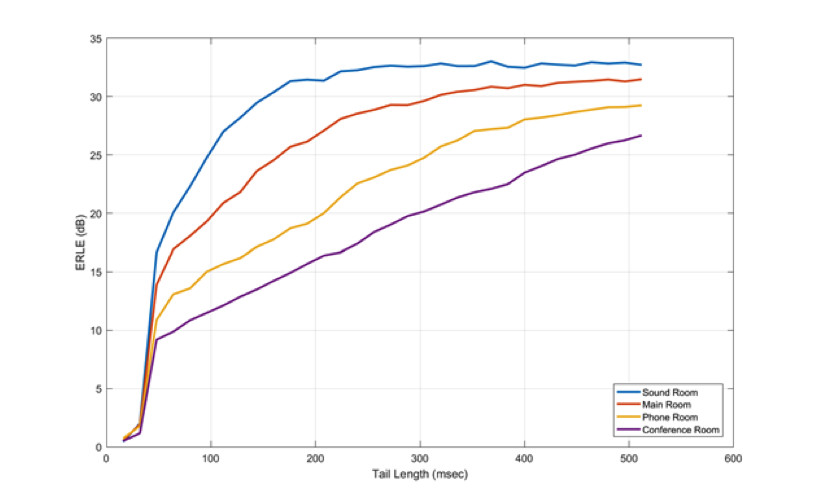
The time period over which the AEC looks for reflections is called the “echo tail length.” The longer the echo tail length, the more reflections can be canceled and the better the algorithm performs. Longer tails, however, require more memory and more processing. Figure 2 shows the performance of the echo canceller in progressively more reverberant rooms. The need for longer echo tails is obvious.

Beamforming
Beamforming allows a mic array to focus on sounds coming from a particular direction. It improves signal-to-noise ratio (SNR) because it helps isolate the user’s voice while rejecting sounds from other directions.
For example, if the user is on one side of the microphone array and an air conditioner is on the other side, the sound from the air conditioner arrives first at the microphone opposite the user, then arrives a fraction of a second later at the microphone closest to the user. The beamformer algorithm uses these time differences to null out the air conditioner sound while preserving the user’s voice.
An array with two microphones has a limited ability to cancel sounds, but an array with three or more microphones can cancel sounds coming from more directions. The fewer microphones, the more the performance will vary as the look angle (the angle between the user’s voice and the front axis of the voice UI product) changes.
Noise Reduction
Although microphone array systems use directional pickup patterns to filter out noise, some noise can be attenuated with an algorithm that recognizes the characteristics that separate the noise from the desired signal and then removes the noise. A noise reduction algorithm can assist with trigger word recognition and also improve voice UI performance after all the other algorithms have done their jobs.
Voice commands are momentary events. Any sound that is always present, or that is repetitive, can be detected and removed from the signal coming from the microphone array. Examples include road noise in automobiles, and dishwasher and HVAC system noise in homes. Sounds that are above or below the frequency spectrum of the human voice can also be filtered out of the signal.
Common noise reduction algorithms used in cellphones tend to highlight the frequency spectrum most critical for human comprehension, rather than the frequency spectrum most critical for an electronic system to isolate and understand voice commands. Most such algorithms actually degrade voice UI performance. To put it simply, humans listen for different things than voice UI systems do.
Figure 3 shows the efficacy of trigger word detection with and without noise reduction. The noise reduction algorithm improves overall speech recognition by 2 dB — a big difference considering that a user’s voice is often only a few dB louder than the surrounding noise.
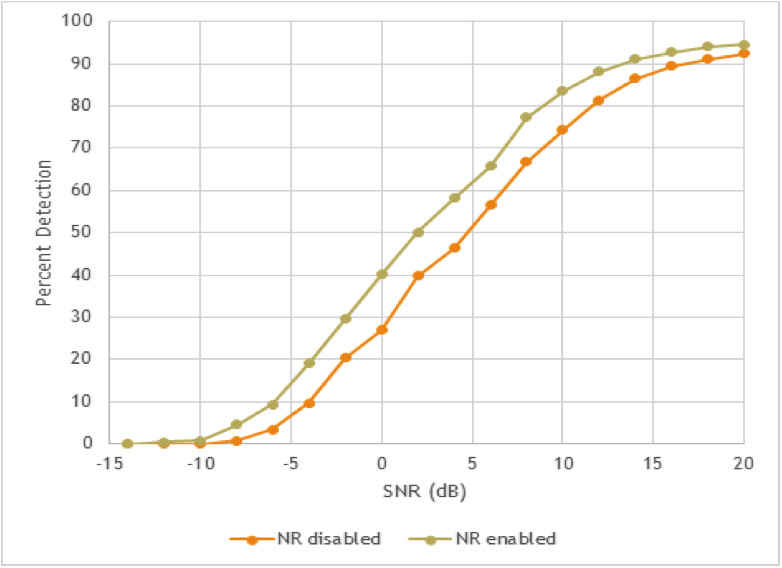
Figure 3. Effects of a noise reduction algorithm on trigger word detection.
Getting deeper into voice UI
About the author
Dr. Paul Beckmann has extensive experience developing audio products and implementing numerically intensive algorithms. Based in Santa Clara, CA, DSP Concepts DSP develops powerful tools for use in dedicated DSPs, DSP cores and SOCs. Prior to founding the company, Paul spent 9 years at Bose Corporation where he developed the first Lifestyle digital home theater product and was awarded the “Best of What’s New” award from Popular Science for contributions made to the Videostage decoding algorithm. He was tasked by Dr. Bose to charter Bose Institute with industry courses on digital signal processing, and holds a variety of patents in signal processing techniques. Paul received BS and MS degrees in Electrical Engineering from MIT in 1989 and a PhD in Electrical Engineering, also from MIT, in 1992.
eletter-10-20-2017 eletter-10-23-2017



