
RTOS debugging, part 5: Deadlock ? when everybody wants the fork
October 17, 2017
A clear indication that you may have a deadlock problem is when multiple tasks suddenly stop executing, although no higher priority tasks are running.
Deadlock is a well-known phenomenon even outside the embedded world. For a general description of deadlock, see this article; it is far better than anything I could ever hope to write.
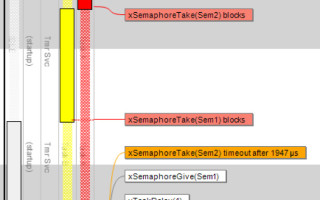
But I digress – back to deadlocks in RTOS-related programming. A clear indication that you may have a deadlock problem is when multiple tasks suddenly stop executing, although no higher priority tasks are running. The Tracealyzer diagram below illustrates a possible scenario: task 1 (yellow) enters a critical section and marks this by taking semaphore 2. Soon after, it is pre-empted by task 2 (red) which has higher priority. Task 2 needs both semaphores 1 and 2 so it tries to grab both. It succeeds with semaphore 1 but semaphore 2 is taken by task 1 so task 2 blocks and task 1 gets to run again.
If task 1 would now release the semaphore and pass execution back to task 2, everything would work as it should but instead it tries to acquire semaphore 1 – which, as we know, is held by task 2. The two tasks block each other and neither of them can continue execution.
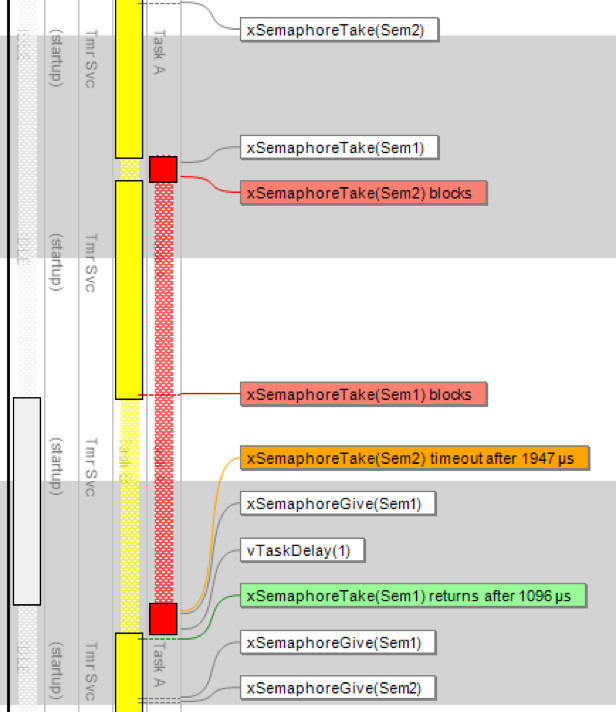
In this particular situation, the deadlock was sort of resolved by a timeout (the orange event). As task 2 could not acquire both semaphores, it released the one it held and went back to sleep, which allowed task 1 to take semaphore 1, run to completion and release both semaphores. But this is hardly an acceptable solution, as a) both tasks were in fact blocked for a considerable amount of time (~1 ms); b) one task failed to acquire the semaphore; and c) it is very likely that this sequence of events will occur again, resulting in another deadlock.
It should be said, though, that it is still a good idea to set timeouts on your lock requests. A timeout may not qualify as a solution to deadlock, but at least it prevents the system from getting stuck in an infinite deadlock. The best way to avoid deadlocks is to avoid critical sections. If that is not possible, at least do everything you can to avoid nested critical sections – as in this example – where you have to lock two (or more) mutexes. Finally, if you cannot escape that either, make sure that the mutexes are always taken in the same order. As long as every task involved follows this protocol, deadlocks cannot occur.
But the mutexes might be taken at different code locations, perhaps in different code files, so nested critical sections might not be obvious in the source code.
Once again, the advice is to avoid blocking on shared resources whenever possible. Instead of using multiple critical sections scattered all over the code (sharing a mutex) you can create a server task that performs all direct operations on the resource and taking requests from client tasks using a message queue, in a non-blocking manner. The server can send any replies via other message queues, specified in the requests, that are owned by the client tasks.



