
Machine Vision in the mW Range Makes IoT Endpoint Inferencing Practical
June 12, 2020
Story
IoT endpoints lie at the frontier of embedded vision. And, as with other frontiers, there are challenges, not least of which is power efficiency.
Machine vision has been rapidly finding its place in the world. Oranges are seen and plucked from trees. Gaze detection targets the dangerously unaware driver. Industrial robots moving around a factory floor rely on it for safe obstacle detection.
IoT endpoints lie at the frontier of embedded vision. And, as with other frontiers, there are challenges, not least of which is power efficiency. Can inferencing at the extreme edge happen without exceeding the node’s power capacity?
This question is worth considering. That’s because inferencing at the edge can avoid indiscriminate transmission of data (only some of which is actionable) to the cloud for analysis. That brings storage costs down. Also, trips to the cloud harm latency and curb real-time capability. Traveling data is vulnerable data, making endpoint processing preferable. It’s advantageous as well for lowering the costs paid to network operators.
A Fresh Approach to SoC Architecture
Yet for all these benefits, a major stumbling block has existed. Power consumption constraints on devices using traditional microcontrollers hamper neural network inferencing at the extreme edge.
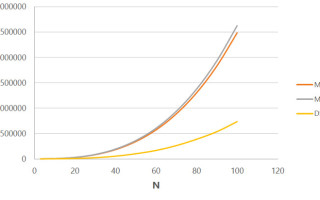
Conventional microcontroller (MCU) performance is not up to cycle-intensive operations. A wake-on-approach solution might rely on machine vision for object classification, which in turn needs the Convolutional Neural Network (CNN) to perform matrix multiply operations that translate into millions multiply accumulate (MAC) calculations (Figure 1).

Figure 1. Until now the problem of microcontrollers not having the efficiency to take on high-volume multiply-accumulate (MAC) has been a stumbling block.
Assorted neural networks exist for MCUs. But, these have failed to catch on as production-ready solutions because the performance needed can’t make it past the power barrier.
Overcoming the power-performance dilemma is why a solution which takes a fresh approach to the processor role and SoC architecture makes sense. Adopting this new approach requires understanding that IoT endpoints have three workloads to tackle for successful inferencing. One is procedural, one is for digital signal processing, and one performs a high volume of MAC operations. One way to address each workload’s unique needs is combining in an SoC a dual MAC 16-bit DSP for signal processing and machine learning and an Arm Cortex-M CPU for the procedural load.
This hybrid multicore architecture capitalizes on DSP dual memory banks, zero loop overhead, and complex address generation. With it any combination of workloads can be processed: network stacks, RTOS, digital filters, time-frequency conversions, RNN, CNN, and traditional artificial intelligence-like searches, decision trees, and linear regression, for example. Figure 2 shows how 2x or even 3x improvement in neural network calculation performance can occur when DSP architecture strengths come into play.
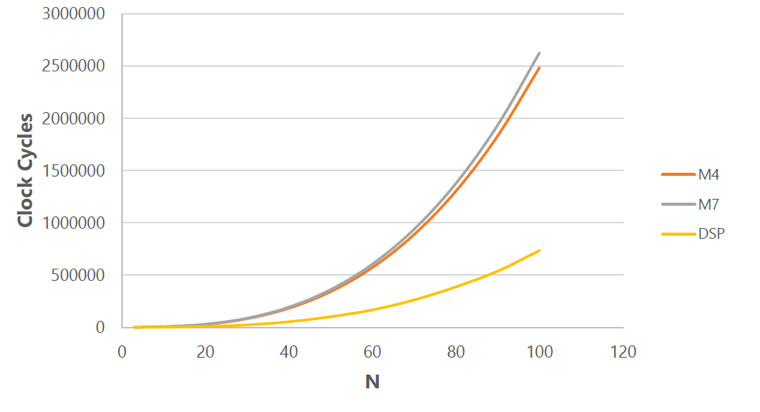
Figure 2. A matrix multiply (NxN) benchmark.
Architecture Change Alone is Not Enough
Whether for embedded vision systems or any others that depend on significantly increasing neural network efficiency, implementing a hybrid multicore architecture is important. However, more must be done when the goal is to bring power consumption down to the mW range. Recognizing this need, Eta Compute patented Continuous Voltage and Frequency Scaling (CVFS).
CVFS overcomes an issue that Dynamic Voltage Frequency Scaling, or DVFS, ran into. DVFS does take advantage of an option for reducing power, namely lowering voltage. The drawback is that maximum frequency decreases when this option is exercised. That problem has pinned DVFS effectiveness into a narrow scope—one defined by a strictly limited number of pre-defined discrete voltage levels and hemmed into a voltage range of a few hundred mV.
By contrast, to bring about consistent SoC operation at the most efficient voltage, CVFS uses self-timed logic. With self-timed logic in place, each device can adjust voltage and frequency automatically on a continuous scale. More effective than DVFS as well as easier to put in place than sub-threshold design, CVFS also differs from these in another important way. And that key difference is that the hybrid multicore architecture noted above multiplies the good that CVFS is already doing.
Production-Grade at the Extreme Edge
Endpoints at the extreme edge, such as those for person detection, have specific needs. While published neural networks are available for use by anyone for these IoT endpoints, they are not prioritized to target these needs. Optimizing these networks using leading-edge design techniques addresses this.
In addition to using advanced design methodologies, the neural network optimization approach that we have taken at Eta Compute centers on our production-grade neural sensor processor, the ECM3532 (Figure 3). It incorporates all the advantages of hybrid multicore architecture and CVFS technology.
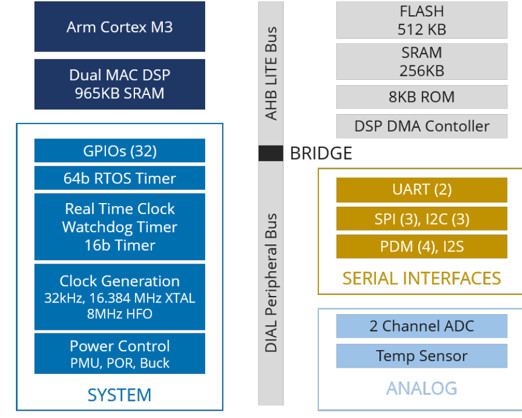
Figure 3. The Eta Compute ECM3532 neural sensor processor’s hybrid multicore architecture, in which an Arm Cortex-M3 processor, an NXP CoolFlux DSP, 512KB of Flash, 352KB of SRAM, and supporting peripherals are integrated in an SoC, makes inferencing at the extreme edge in the mW range realizable.
Knowledge Gained
What tests such as the one whose results Figure 4 presents have revealed is that power costs do not have to rise to unacceptable levels in order to bring deep learning to embedded vision systems. While there is no one magic wand for feeding power-hungry neural networks, an approach that combines MCU power efficiency and DSP strengths along with network optimization can help applications avoid the security, latency, and inefficiency problems that relying solely on cloud computing causes.

Figure 4. In a test of a person detection model, average system power, which included the camera, of 5.6mW was achieved. For this test, the rate was 1.3 inferences per second, but refining optimization further should lower average system power still more to 4mW, at the same time increasing the rate to 2 inferences per second.

Semir Haddad is the Chief Product and Strategy Officer at MicroEJ, and is in charge of product strategy and ecosystem, for the company that makes everything software defined. Semir has more than 20 years of experience working with industry leaders and startups, bringing innovative technologies to industrial and consumer markets.



