
Low-latency, distributed database architectures are critical for emerging fog applications
September 10, 2018
Story

There?s increasingly large and fast data coming from a very broad spectrum of IoT devices, coupled with critical latency requirements.
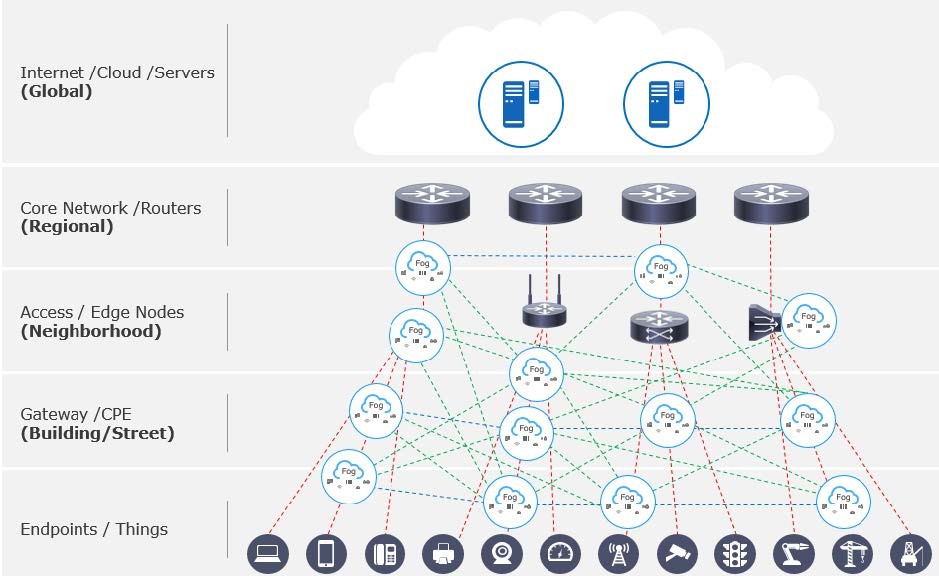
Internet of Things (IoT) solutions present a unique challenge for any database. There’s increasingly large and fast data coming from a very broad spectrum of IoT devices, coupled with critical latency requirements. Given this, the data’s processing and analysis must increasingly be handled at the network edge, close to the sensors, actuators and other IoT devices.
We no longer have the luxury of being able to crunch IoT data in a cloud environment, where there is seemingly limitless compute and storage resources, because the latency would be unacceptable. Thankfully, there are powerful database and platform solutions tackling this challenge head-on, which we’ll explore below. But first, let’s review some of the data requirements unique to IoT environments.
Edge computing has increasingly become metaphorical for table stakes, given the volume, velocity, variety and veracity (the “four V’s”) requirements of IoT and big data, and the distributed nature of many of these use cases.
So, is there a way to maintain the capabilities we have long enjoyed (and the very reason we’ve had a massive trend to cloud computing over the past 10 years) if we move back to distributed computing at the edge? Can we have our cake and eat it, too?
Bringing Cloud Principals to the Edge with Fog Computing
Fortunately, in this case – with the popularization and growing trend of fog computing – the answer is yes. The solution is to bring cloud principals to the edge, where the fog and cloud environments operate in tandem to handle complex IoT use cases. When you have critical latency requirements, for example with smart city IoT use cases such as gunshot detection or criminal face recognition, your data must be handled by ruggedized fog nodes located close to IP cameras and other sensors.
Non-latency critical data can still be synchronized to the core or cloud. In this way, data from all edge devices and fog nodes in your IoT solution can be aggregated at a core level (for example, a city block in the smart city use case), and ultimately to the cloud or data center environment for business intelligence and other analytics.
With fog computing, we refer to data communication between IoT devices, edge devices, fog nodes and the cloud as “north-south” communication, and data communication between the edge/fog nodes across the system as “east-west” communication. For this to be effective, we must have common cloud or datacenter environment capabilities at the edge, such as machine learning, deep learning and other artificial intelligence.
This presents the next challenge: how do we handle these needs, given the distributed nature and modest storage and compute capabilities in edge devices and fog nodes? Having fog and cloud environments operating in tandem is critical. For example, with machine learning, we need to train models in the cloud where we have vast compute and storage resources. Then we need to deploy those trained models to the fog nodes and/or edge devices, so they can be served close to IoT devices to minimize latency.
A Database for the “Intelligent Edge”
The “intelligent edge” has arrived and rescued us from these seemingly unsolvable problems (or Kobayashi Maru for you “Star Trek” fans). The edge has become the battleground for IoT today, but is there a database on the planet that can handle this massively large and high-velocity data from potentially thousands of sensors, cameras and other devices? One that can process that data in real-time, with many different database models, and with a small footprint?
The industry is addressing this and the answer is: yes.
There are now solutions coming to market that offer fast performance and the ability to ingest millions of writes per second with less than 1ms latency at the IoT edge. That’s powerful. Since these solutions can be delivered with a small hardware and software footprint, they are perfectly suited to live on fog nodes, edge gateway devices, and even IoT devices in some cases.
Some of these solutions, such as Redis Enterprise, feature many native data structures (sets, sorted sets, lists, hashes, streams, etc.), providing ultimate flexibility for IoT application developers. Furthermore, with the many modules that already exist to extend it, these solutions can feature multi-model databases that can handle very diverse workloads required at the IoT edge: time-series, graph, machine learning, search, etc.
A Simplified Architecture
Rather than deploying six different databases to support these needs, these platforms can manage them all, tremendously simplifying your architecture. Many mission-critical IoT use cases are distributed geographically across many regions, which represents another use case that can be handled gracefully by platforms coming to market that feature high availability, active-active (with CRDTs), disaster recovery, and auto scaling capabilities.
Now that we’ve shown there are databases worthy to take on the intelligent edge, you might wonder which platform is best-suited for running them at the IoT edge? There are many variables and options, of course. At Redis Labs, we’ve partnered with Microsoft Azure on IoT edge solutions. The key is to provide the customer with fast general data storage, a message broker between Azure Edge modules, streams processing, a time-series database, and in-memory processing (machine learning model serving, graph processing, etc.) for the best possible performance.
The IoT community will significantly benefit from joint IoT edge solutions. However, integrating the right database with the right intelligence IoT edge solution is critical to the success of all IoT endeavors.
Rob Schauble is a senior executive with strong global business and technical leadership skills. His 25+ year proven track record includes creating innovative products and services and developing new businesses. He is currently the VP of IoT & Emerging Technologies at Redis Labs, driving Redis Enterprise to become the leading IoT edge database. Prior to that, he led the formation and success of Esgyn in Silicon Valley and China to commercialize Apache Trafodion, an open source, web-scale, transactional database on Hadoop.



