
PCI Express bridging: Optimizing PCI read performance
November 01, 2008

Commercially available bus bridges can eliminate performance problems using Short-Term Caching.
PCI Express (PCIe) is now a ubiquitous interconnect standard on PC chipsets and embedded processors. Although using a bridge can provide existing PCI devices with a cost-effective upgrade path to PCIe, the resultant PCI reads produce additional latency that can significantly hinder system performance. Craig explores how implementing PCIe bridges can resolve performance issues caused by PCI reads.
While PCIe is replacing the original PCI bus standard, many
peripherals and devices such as FPGAs and I/O modules still use PCI. Components
without an integrated PCIe interface need a bridge from the PCI bus to PCIe.
Two application examples that require a bridge include a PCIe add-in processor
card that uses a PCI-based DSP for communications applications and an embedded
video recorder that uses I/O devices with PCI to connect to an embedded
processor with PCIe ports.
In these and other systems, adding a bus bridge presents
design challenges. Performance often depends on the bridge's PCI read
performance. Because of limitations in the older PCI protocol, performance
problems can arise once a bridge is introduced. These problems can be
eliminated using commercially available bus bridges to maximize system
performance.
Heavy-duty reading burdens PCI devices
Devices on the PCI bus often depend heavily on reading large
amounts of data from the host processor. PCI I/O devices typically control data
movement in the system and initiate both read and write cycles to the host's
memory. For example, the host processor might organize and orchestrate data
movement by writing to registers on the peripherals to set up DMA transfers in
the peripherals, but it will remove itself from data movement to focus on other
tasks. The peripheral device will then read or write data to service the DMA
request. At other times, the processor might read status information and write
to registers for control. This traffic typically does not involve high
bandwidth or contribute significantly to overall system performance.
In the case of a processor add-in card, its DSP must read
data from the host PC memory for data processing or compression tasks.
Likewise, an embedded processing system such as a security DVR will capture and
compress video that will be written to disk storage via the disk controllers.
The disk controllers achieve this by reading data from the host's memory via
the PCI bus.
Writes from PCI peripherals to a bridge are usually posted in
an internal write buffer to overcome the inherent performance penalty a bridge
imposes. However, PCI reads introduce problems as the PCIe bridge must retry
the peripheral device until it obtains the requested data from the host's
memory. This usually involves attempting to read many small PCIe packets, thus
adding delay.
While the PCI-X protocol skirts this problem through split
transactions, the conventional PCI protocol does not implement this feature.
Additionally, some PCI devices were designed to automatically release the bus
after receiving one or two cache lines of data, compounding the performance
challenge with PCI reads.
Take the DSP processor card application, for example. This
particular DSP uses a 32-bit PCI interface. As with many PCI devices, it will
read one or two cache lines of data before releasing the PCI bus. A cache line
in this case consists of 16 to 128 bytes depending on the system design and
device capabilities.
The card will read large blocks of raw data for processing,
such as audio bit streams for processing within telecom applications. In legacy
systems where the DSP communicates with the host processor directly over a PCI
bus, read performance will be better than after a bridge is added because of
the additional latency for each transaction.
Bridge-induced performance deterioration
Introducing a PCIe bridge can
cause a significant hit in performance. This read performance degradation can
occur through the following process (Figure 1):
- The DSP will initiate a read from PC main memory. The bridge will latch the
transaction and keep retrying until the bridge receives the data. - The bridge will pre-fetch data from memory and store it in the internal buffer.
- The DSP will read a portion of the data (one or two cache lines) and then
disconnect, releasing the PCI bus. - Once disconnected, the bridge will discard any remaining data in its buffer. With
the next read initiated by the DSP, the bridge will need to fetch the data
again, retrying until the data is available for the DSP.
|
|
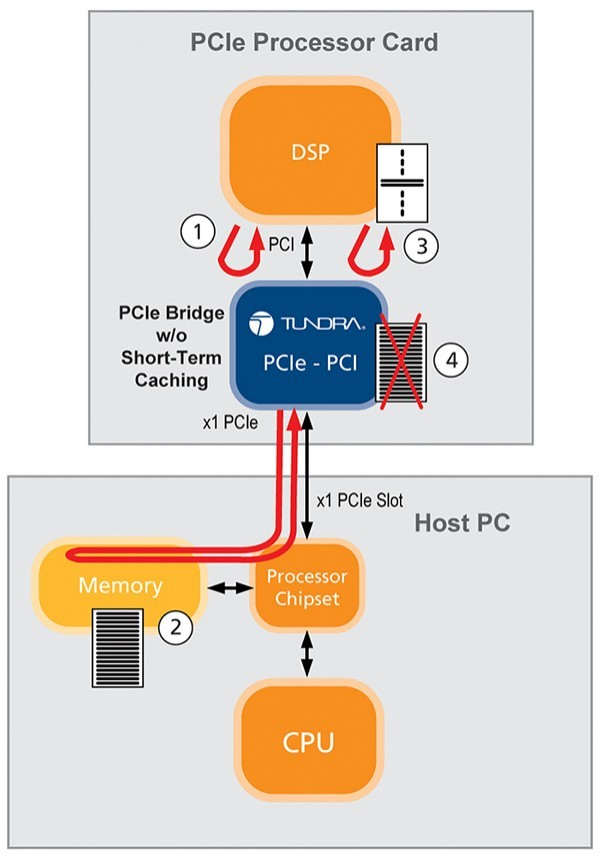
In this example, step 4 introduces significant delay between
read transactions, which dramatically affects read performance. The impact on
read performance that results from using a PCIe bridge can thus
diminish system performance to a much greater degree than what can be achieved
using the PCI bus directly.
Consider another common situation using an embedded DVR. In
this case, the system must write continuous streams of compressed video data to
disk for storage and later retrieval or analysis. In this system, one or more
SATA disk controllers will read the video data from the system's main memory to
store in the attached disk array. These types of systems may contain additional
peripherals such as an Ethernet controller sharing the PCI bus.
Like the previous example, bus efficiency in the embedded DVR
is seriously affected by continuous data reads followed by a bus disconnect and
many retries and pre-fetches, as illustrated in Figure 2.
|
|

As evidenced by the PCI_TRDYn (PCI Target Ready) trace that
indicates where data is being read, there is a large gap between the first read
(step 3) and the next read (step 6). This translates into a significant
reduction in the maximum speed at which video data can be written to disk,
therefore limiting system performance. In this case, maximizing the speed at
which video data can be written is critical to the end product, providing the
ability to store as many high-quality video channels as necessary for surveillance.
Solving the problem: Short-Term Caching
Tundra's PCIe bridges (Tsi381, Tsi382, and Tsi384)
incorporate a feature known as Short-Term Caching (STC) to help overcome this performance challenge. STC
allows data to be pre-fetched from the attached PCIe device during an initial
PCI read cycle and temporarily stored in the bridge for quick turnaround during
subsequent read cycles. Data that would be read in subsequent reads is not
immediately discarded when the requested device stops the transaction.
STC's effect on performance can be dramatic compared to the
initial bridging situation. Take the previous example of the embedded DVR but
with a Tsi381 bridge added to the system. By enabling STC, subsequent reads are
not delayed because they remain in cache. Furthermore, the bridge does not have
to reread the data from memory after the first read, ensuring that the bus is
used efficiently (see Figure 3).
|
|

To demonstrate the difference in performance, compare the
timing for the PCI bus before and after enabling STC (see Figure 4). In this
example where the system performs 32-bit reads per device, the two devices can
perform seven reads during the same period that only two reads were performed without
STC. Hence, overall system throughput can be improved by a factor of more than
three with STC. For a system with a single device performing such reads, the
improvement will be even greater.
|
|

PCIe bridges allow developers to further modify the system by
adjusting the following parameters:
- The time that data is held in the cache. This allows the designer
to ensure that stale data is discarded and pre-fetched once stale. - PCI read pre-fetch length. Ideally, the bridge should not
pre-fetch more data than what the PCI peripheral typically requires, so
designers can set this parameter based on the typical transfer lengths
expected.
Depending on the system design and device behaviour,
designers can improve overall performance or performance for critical functions
by adjusting the pre-fetch length and short-term cache discard timer.
Bridge options help eliminate bottlenecks
Designers who use PCIe bridges to migrate designs from PCI to
PCIe face considerable design challenges. Reads initiated by PCI peripheral
devices introduce additional latency, which contributes significantly to
overall system performance. PCIe bridges such as Tundra's Tsi381 give designers
options to tune bridges, providing optimum system performance. Using STC, these
bridges can easily remove performance bottlenecks associated with PCI reads.
Craig Downing is
product marketing manager for PCIe products at Tundra Semiconductor, based in
Ottawa, Ontario, Canada. During the past 20 years, he has held several
engineering, sales, marketing, and product management positions at various
high-tech companies with experience in applications including videographics,
industrial machine vision, image processing systems, and media processors for
consumer electronics. Craig has a Bachelor of Engineering (Electrical) degree
from McGill University, Montreal.
Tundra Semiconductor
613-592-0714
[email protected]
www.tundra.com



