
Cross-industry semantic interoperability, part five: Towards a common data format and API
September 21, 2017

Part four discussed the intersection of business and device ontologies, and how elements of both can improve scalability. Now we discuss how a common data format and API can leverage these ontologies.
This multi-part series addresses the need for a single semantic data model supporting the Internet of Things (IoT) and the digital transformation of buildings, businesses, and consumers. Such a model must be simple and extensible to enable plug-and-play interoperability and universal adoption across industries.
Part four discussed the intersection of business and device ontologies, and how elements of both can improve scalability. In part five we discuss how a common data format and application programming interface (API) can leverage these common ontologies.
This is intended to be a living series that incorporates relevant emerging concepts and reader comments over time. The community's participation is encouraged.
Navigate to other parts of the series here:
- Cross-industry semantic interoperability: Glossary
- Cross-industry semantic interoperability, part one
- Cross-industry semantic interoperability, part two: Application-layer standards and open-source initiatives
- Cross-industry semantic interoperability, part three: The role of a top-level ontology
- Cross-industry semantic interoperability, part four: The intersection of business and device ontologies
When you first start off trying to solve a problem, the first solutions you come up with are very complex, and most people stop there. But if you keep going, and live with the problem and peel more layers of the onion off, you can oftentimes arrive at some very elegant and simple solutions. Most people just don’t put in the time or energy to get there.
– Steve Jobs
Managing data in a world of objects
In the emerging digital world, billions of people, systems, and devices will interact in real-time, requiring new and disruptive approaches to distributed data management, interoperability, and rule-based event processing.
In addition to aligning ontologies, “IoT standards” and “business standards” consortia need to converge on a common data exchange format and API model that are adequately abstracted to support plug-and-play interoperability among broad-based, cross-industry use cases.
Distributed data management and interoperability rely on a common ontology (for semantics) and common data format (for syntax) that allow services to recognize and interpret structured data exchanged among connected systems.
In this article, “object management” refers to the mechanisms to create, store, update, access and share the state of ontology object instances in a distributed environment.
What is a service?
The term “service” takes on different shades of meaning depending on the context. As a result, there is a cloud of confusion surrounding the notion of services as one tries to distinguish between application services, domain services, infrastructural services, service-oriented architecture (SOA) services, and the like. In all these cases, the term “service” is valid, however the roles are different and can span all layers of an application[15].
In Domain-Driven Design (DDD), a “domain” service operates upon domain concepts (ontology classes), is very granular (as in “micro” services), and can be considered an encapsulation of a type of process. “Application” services provide a hosting environment for domain services and expose the functionality of the domain to external services as an API. Application services operate upon identity values and primitive data structures of a common information model (within a top-level ontology).
A model for services in a foggy world
Given the massive amounts of data from IoT and the requirements for real-time communication flows, Gartner predicts that by 2022, 75 percent of enterprise-generated data will be created and processed outside the data center or cloud. It’s clear that cloud-only approaches can no longer keep up with the necessary volume, latency, reliability, and security challenges.
A distributed computing model (fog computing) can address these challenges by providing a standard, universal way to manage, orchestrate, and distribute the necessary resources and services to enable functionality and interoperability for the digital world, bridging the continuum from cloud to things (Figure 50).
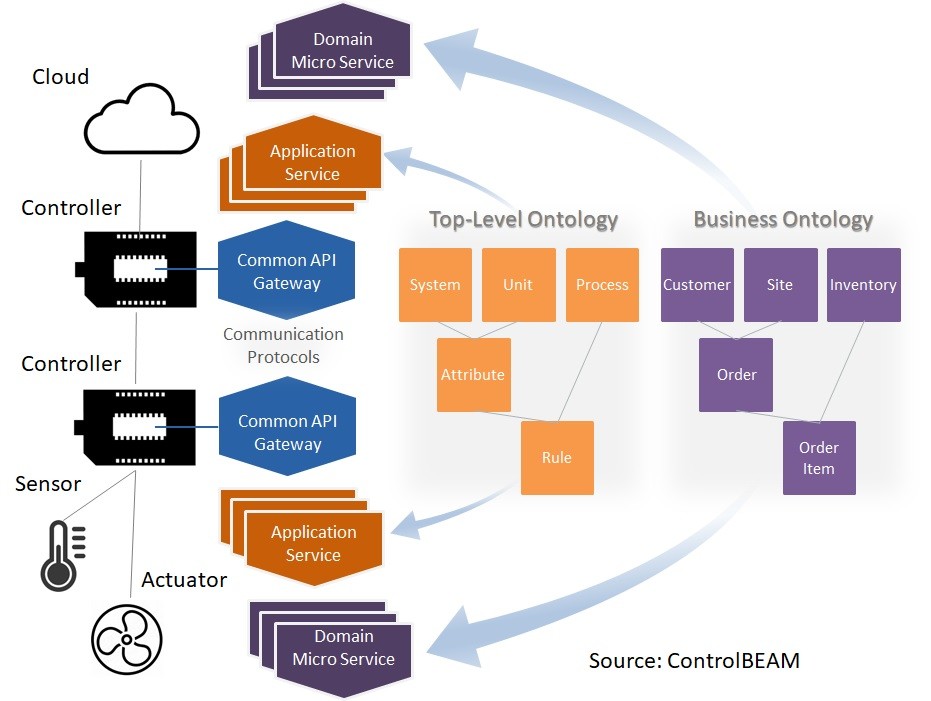
Figure 50. A service model for semantic interoperability and fog computing
This model can “blend” trending architectural styles (such as DDD, model-driven design, event sourcing, and command query responsibility segregation (CQRS)) to define simple and scalable application services for object management within a system of interoperable systems. These systems can span the subsystems of IoT devices, businesses, vehicles, and cities. And these services can leverage a top-level ontology and information model (see part two) to support system connections, unified data exchange, event and query processing, unit and identifier conversion, and semantic annotation. To scale, these services must be stable, unchanging, transport-independent, and embeddable in any type of machine, from edge controllers to cloud servers.
The model can define a set of object management services (similar to the IETF’s Extensible Provisioning Protocol (EPP)) that are not explicitly tied to specific objects and can extend to objects across all ontology classes. While object management parallels object-oriented programming, this service model can represent a metadata abstraction from programming that is similar to concepts in model-driven development. These services can create metadata and interpret that metadata at runtime. The metadata representing an ontology can be maintained in a repository that is completely abstracted from any programming environment. Low-code platforms-as-a-service (such as Mendix) can leverage this service model to provide inherent interoperability among applications executed entirely by metadata interpretation.
While there is a strong relation between service and security models, this part in the series will focus on semantic-related services agnostic to any specific security model.
A grid for a message payload
To create value, data generated by IoT devices is increasingly timestamped within a time series and transmitted at intervals or upon state changes. As business applications become increasingly IoT-centric and built around event-driven architectures, data from business events can also be structured as a time series. Query responses can comprise the current state of device and information objects based on these event changes. Time-series and query-response data represent the majority of distributed data exchanged, and are most efficiently contained within a grid (tabular) structure.
A grid (similar to a Haystack Grid) can be utilized as the core data format for distributed data management, and can be transported in a syntactical format suitable for a specific communications protocol (Figure 51). For example, a grid can be encoded as a JavaScript Object Notation (JSON) array (two-dimensional) for transport via an HTTP message. Or it can be encoded as a Concise Binary Object Recognition (CBOR) array for transport via CoAP.

Figure 51. Connected systems exchange data contained within serialized two-dimensional grids.
Syntactical formats supported by consortia-defined data exchange services vary (Figure 52). Services that were initially designed primarily for server implementations (GS1 EDI and IETF EPP) support XML, while those targeting resource-constrained devices support more compressed encoding formats (such as JSON and CBOR). Grid data can be encoded within any of these formats.
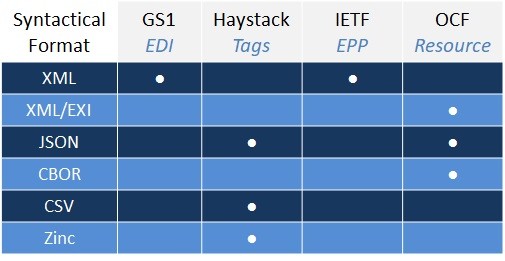
Figure 52. Data serialization/encoding formats for message payloads
A common API gateway to application services
Rather than exposing a myriad of application-defined services (typical SOA services), a Common API Gateway can be implemented within a controller device as the single entry point for all inbound messages from connected systems. The gateway can authenticate each message and forward the de-serialized grid payload to an application service, which might in turn invoke other services that generate outbound messages handled by the gateway.
By exposing a single common API as the “front door” for all controller devices, the complexity of different device types and partitioning of microservices can be abstracted away. The device can then be turned into a service (device-as-a-service) and used by other services.
Based on the type of grid data, the gateway can invoke separate event and query-processing services (similar to the CQRS architecture), which can update and retrieve the state of objects that persist in an “event store” (Figure 53).
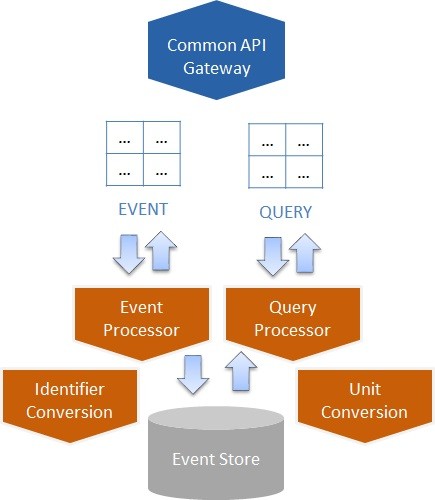
Figure 53. Event/query responsibility segregation and interaction with an event store
An event store for a time series
What do self-driving Teslas, autonomous Wall Street trading algorithms, smart homes, and same-day order fulfillment services have in common?
These applications rely on a form of data that measures how things change over time, where time isn’t just a metric, but a primary axis. This is time-series data. And it’s starting to play a larger role in our world, far beyond data streams from sensors. In fact, time-series databases (TSDBs) have emerged as one of the fastest growing categories of databases that can be efficiently indexed, queried, shared, and analyzed.
When applied to the concept of “event sourcing,” a TSDB can be considered an “event store” that persists the state of objects as a sequence of state-changing events within a time series. Whenever the state of an object changes, a new event is appended to the event store, which is inherently atomic. By disallowing changes or deletions of events, an event store can provide a reliable audit log of all changes made to an object.
In Figure 54, an event store reflects the creation of a Location object (instance) from an event at 02:15 on 9/18 that assigned an owner party to the new object. The event also assigned an identifier and class to the object, which form its primary key. This key is included in all subsequent events that change the object’s state by assigning values to attributes. The current state of the Location object can be derived from the latest event for each attribute of the object.

Figure 54. Obtaining current state of a Location instance (object) by “sourcing” time-series events in an event store
An event can delete (or undelete) an object by assigning a Boolean value to a “Deleted” attribute of the root Object class. With this methodology, events and event processing can effectively create, update, and delete objects, displacing the need for separate commands and command processing (reading can be handled by queries and query processing).
Blockchain or event store?
Blockchains and event stores are both data-storage mechanisms that can provide an append-only audit trail of object state changes in a distributed environment.
While blockchains are receiving all the recent hype, the event store/event sourcing approach to data storage can provide many of the benefits promised by blockchain without the overhead, community building, and risk of becoming a slave to the miners.
Blockchains are based on the concepts of ledger and transaction, which are very applicable to the financial industry. However, it’s questionable whether these concepts are well-suited to support a system of interoperable device systems.
A “blended,” scalable approach may combine the granularity of object-oriented events within an event store with the anti-tamper verification of blockchain.
A service for event processing
Grid data representing time-series events can be structured in a common format that enables efficient processing by all event-consuming application and domain services implemented on a controller device. This Common Event Format can support both device and business events that reflect object state (attribute value) changes. While the top grid in Figure 55 shows human-readable values within this format, the actual values can reflect machine-readable identifiers as shown in the bottom grid.
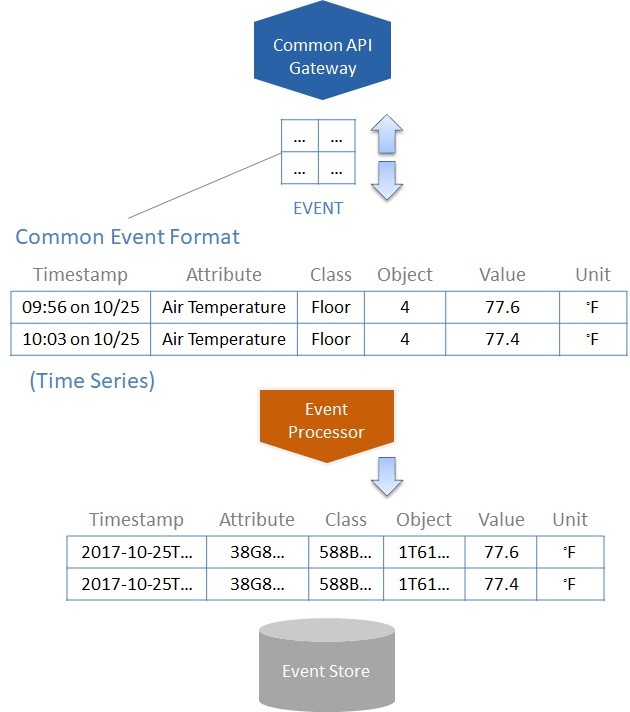
Figure 55. Using an event processing service to persist time-series events from a common format
The common API gateway can invoke an event processing service to process inbound time-series events and can publish outbound events to connected controller systems.
The event processor can orchestrate the processing of events among all system processes (microservices) based on their rules, which can emit new events (including confirmation events similar to OCF post/response). The event processor can post events to an event store to persist state (similar to Haystack’s hisWrite operation).
A Data Map, based on a top-level ontology, can be referenced by an event processor receiving data from a sparsely-resourced sensor. The event processor can then annotate the semantics it receives from the sensor with the semantics included in the Data Map instance to populate all of the metadata within a Common Event Format (Figure 56).

Figure 56. Using an event processing service and top-level ontology to annotate time-series semantics
This annotation can include converting consortia-specific data formats into a Common Event Format (Figure 57). For example, a temperature sensor can submit a delimited collection of name/value pairs that provide semantics in addition to the value. This data can be converted to a grid that includes just the value-side, since the grid column positioning corresponds to the specific data element.
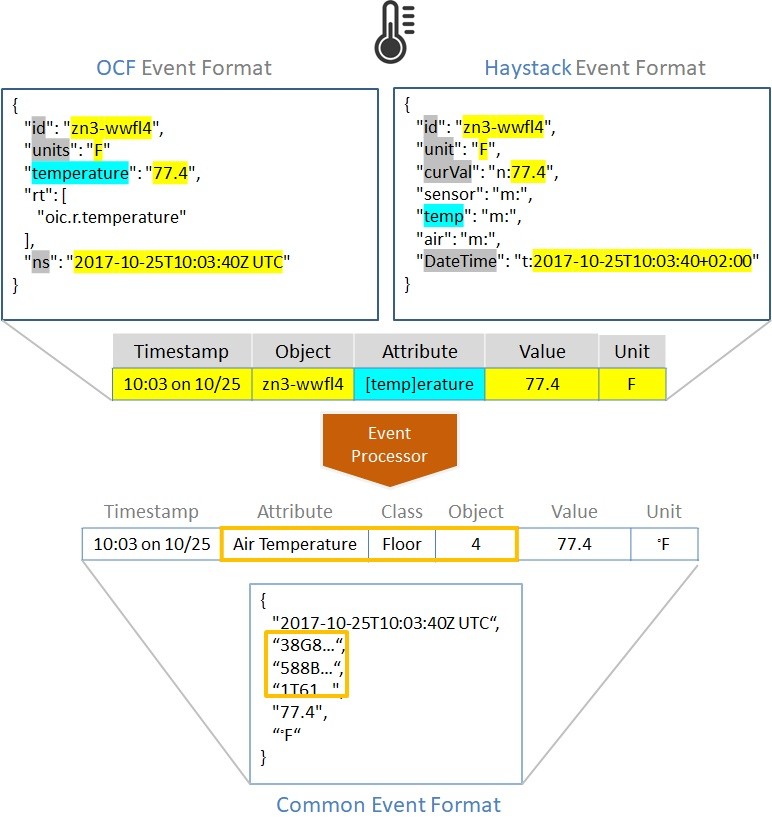
Figure 57. Using an event processing service to convert disparate event formats to a common format
An event processor can reference system attributes (Figure 58) modeled in a top-level ontology that define read/write settings (similar to OCF’s readOnly property). Based on these settings, the event processor can monitor (read) and alter (write) the operating state of component devices (sensors, actuators) connected to the controller.

Figure 58. Using an event processing service to get/set fan speed based on read/write settings of a system attribute instance
For example, if a system attribute enables both read and write of a fan’s speed attribute, the event processor can retrieve the current value from the fan (similar to OCF get) and also set its value (similar to OCF post) based on a time-series event.
A system connection for pub/sub
An event store can act as a “service registry” that stores events that define system connections and the attributes of connected systems. A system connection, modeled in a top-level ontology, can represent a real-time data subscription (similar to Haystack “watch”). When a device initiates a system connection (EPP session) with another device, the device can respond with its system attributes. Devices are then able to exchange events and queries that include common attributes between their systems. These attributes represent the internal input/output of the system’s processes.
For example, a controller’s HVAC system can be connected to another controller’s Airflow Control system. Both systems can reference a “Speed” attribute of a “Fan” device defined in a common ontology. A process (domain microservice) of the HVAC system can produce a time-series event that changes fan speed when a triggering event occurs (such as an air temperature change). The event processor of the HVAC system controller can publish this event to the Airflow Control system controller, which invokes its event processor to change the speed of a connected fan motor.

Figure 59. Using an event processing service with an event store (registry) to publish events to connected systems with common attributes
State management for digital twins
From design to predictive analytics, the use of “digital twins” is becoming more prevalent. The concept is pretty simple – basically a twin is referring to a dynamic software model (digital instantiation) of a real-world physical asset. This model enables you to expose and interact with the inner workings of a device and its connected systems in real-time. The digital twin can consolidate sensory and contextual information that allows organizations to benefit from asset intelligence. The end result is the potential to create higher asset performance and allow the manufacturer to manage equipment as-a-service.
A common service model comprising object management services can manage the state of digital twins by supporting synchronization and publishing of state changes (similar to Eclipse Ditto).
A service for query processing
Grid data can represent query requests and responses. A query request can be structured in a common format that enables processing by an application service implemented on a controller device.
The Common API Gateway can invoke a query processing service to process inbound query requests structured in a Common Query Format (Figure 60). The query processor can retrieve the current state of related objects from the event store that meet the query criteria and return an outbound query response to the gateway to return to the requesting service.
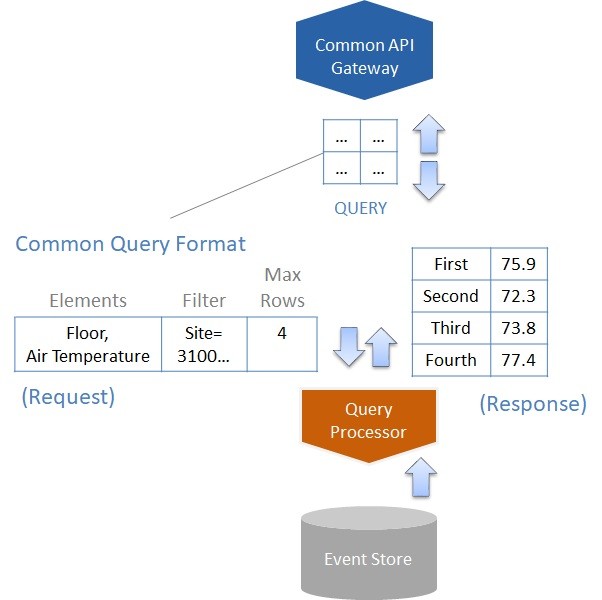
Figure 60. Using a query processing service and common query format to retrieve object state from an event store
A query processor can reference vocabulary terms (Figure 61) modeled in a top-level ontology to provide National Language Support for global applications. A Common Query Format can include an element that specifies the human language for data included in the query response. For example, if the query illustrated in Figure 60 specified the “Spanish” language, the names of the floors returned in the response grid would appear in Spanish rather than English.

Figure 61. Using a query processing service and top-level ontology to retrieve vocabulary terms in a requested language
A service for identifier conversion
An application service can reference attributes and units (Figure 62) modeled in a top-level ontology to convert alternate identifiers included in a time-series event.

Figure 62. Using an application service and top-level ontology to convert alternate identifiers within time-series events
For example, an event processor can invoke a service to convert an alternate unit identifier (for example, “degF”) that is qualified by an attribute identifier (for example, “3861…”). The service can reference the Unit object that includes the identified attribute (“ISO Code”) with the value of the alternate identifier (“degF”). The service can convert the value of the unit identifier within the event to the primary identifier of the Unit object (“◦F”).
As another example, the conversion service can convert alternate identifiers used to identify the “Object” and “Value” elements within a time-series event generated by an RFID sensor. The “Value” element in Figure 63 contains an alternate location identifier (“0123456789012”) that is qualified by an attribute identifier (for example, “urn:epc:id:sgln”) adhering to GS1’s EPCIS standard. The conversion service can reference the Location object that includes the identified attribute (“GLN”) with the value of the alternate identifier (“012345…”). The service can convert the “Value” element within the event to the primary identifier of the Location object (“3100 Main…”).
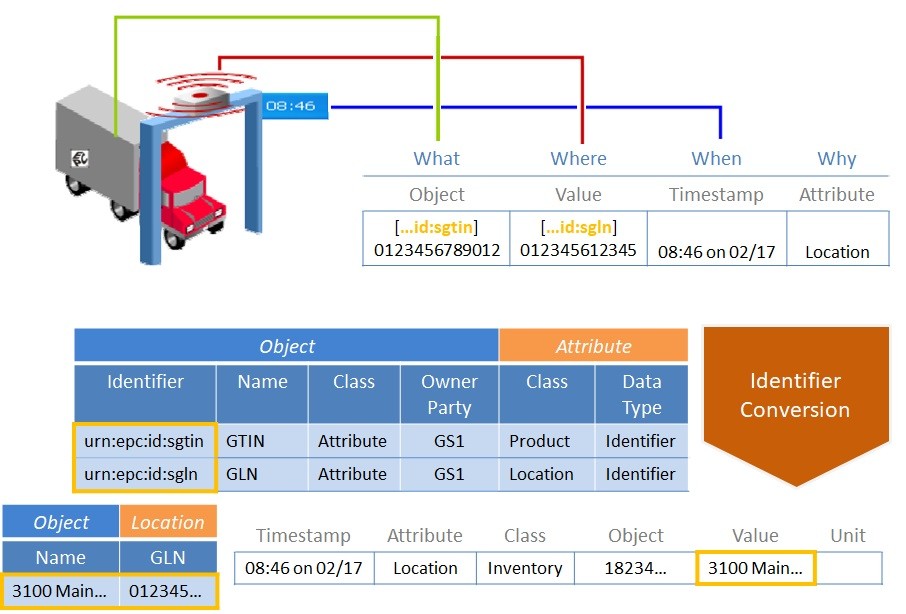
Figure 63. Aligning GS1 EPCIS events with a Common Event Format and converting GS1 Keys
A service for unit conversion
An application service can reference measurement units modeled in a top-level ontology to convert “Unit” and “Value” elements included in a time-series event.
For example, an event processor can invoke a service to convert a temperature value (“77.4”) in Figure 64 from Fahrenheit to Celsius by referencing the “Conversion Factor” and “Offset” attribute values of the associated Unit objects.
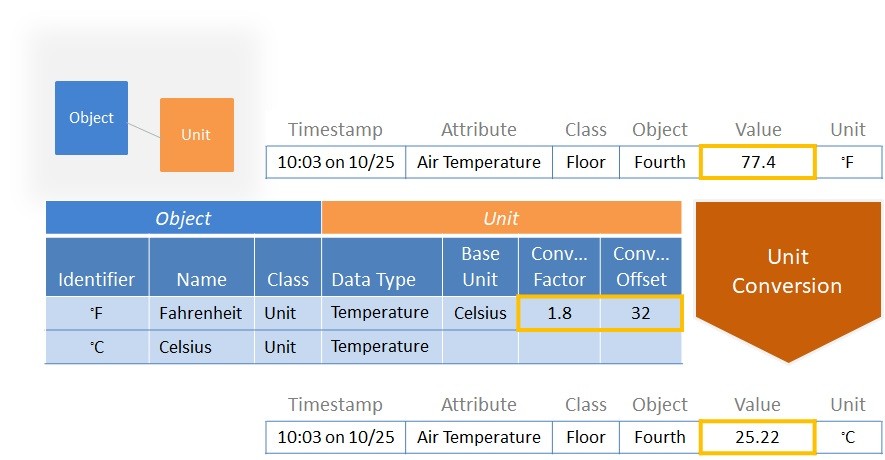
Figure 64. Using an application service and top-level ontology to convert measurement values and units within time-series events.
Domain microservices for domain-specific ontologies
While application services are intended to be stable and unchanging, domain microservices can be implemented dynamically as processes and rules evolve to effectively meet the objectives of system owners (parties).
Each system can contain a collection of microservices (encapsulations of processes and rules) that references attributes within domain-specific ontologies (for example, healthcare, retail, building automation, and so on). These narrowly-defined, collaborating microservices can consume time-series events based on rules and produce time-series events from their actions.
An event processor can orchestrate the execution of domain microservices for complex event processing.
Figure 65 provides an example of a domain microservice that can reference scene definitions modeled in a domain-specific ontology to change the “scene” of a location based on a triggered event (such as a time change).
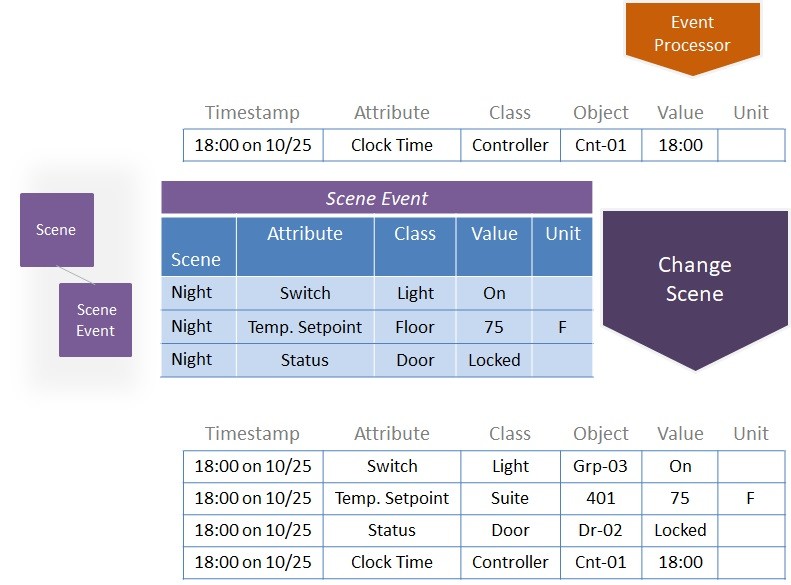
Figure 65. Using a domain service and ontology to change a “scene” within an office suite
Another domain microservice can reference business information objects modeled in a common business ontology, to generate events that define a replacement order based on a triggering event from failing equipment (Figure 66). The same controller that alters the state of connected component devices (like sensors and actuators) can also be used to alter the state of information objects (such as an order) associated with connected business systems.
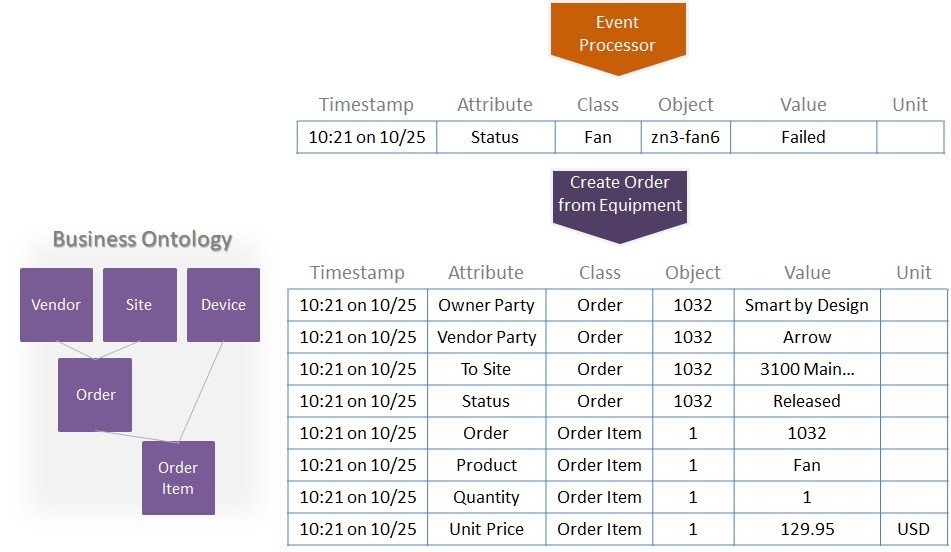
Figure 66. Using a domain service and common business ontology to generate a replacement order from an equipment failure
Together, a common service model and common ontologies can form a “common object management framework” that supports a semantically interoperable, peer-to-peer system of systems. This framework can break down data silos, eliminate complex system integrations, and unify information spaces using only metadata.
Part six discusses managing and distributing semantic metadata to improve scalability.
For term definitions, see the Glossary.
Victor Berrios is Vice President of Technology for Zigbee Alliance and has twenty years of experience in the wireless communication industry. He is a recognized expert in the short-range wireless industry as evidenced by his contributions to the RF4CE Network; Zigbee Remote Control, Zigbee Input Device, Zigbee Healthcare, and Zigbee Low Power End Device Specifications. He was recognized by the Continua Health Alliance as its Spring 2011 Key Contributor to the success of the Test and Certification Work Group.
Richard Halter was the Chief Technology Architect for the Association for Retail Technology Standards (ARTS) for over 18 years. In this role, Richard was responsible for all ARTS artifacts including Unified POS Devices, Operation Data Model, POSLog XML Schema, Integration Technical Reports, and best practices papers. In addition, he contributed to the ARTS Data Dictionary, describing thousands of retail technology terms. Richard was a member of Conexnus (convenience store group), HITIS – Hotel Industry, ARTS, and GS1.
Mark Harrison provides technical consultancy to GS1 in areas including end-to-end supply chain traceability and blockchain, Linked Data/Semantic Web, and the GS1 SmartSearch vocabulary. As former Director of Cambridge Auto ID Lab, Mark contributed to development of GS1 EPCglobal open standards for networked RFID (including EPC Information Services (EPCIS), Discovery Services, Networked/Event-based Electronic Pedigree, and EPC Tag Data Translation).
Scott Hollenbeck is Senior Director of Verisign's Registry Services Lab. Scott has developed expertise in the Domain Name System (DNS) and is the author of the Extensible Provisioning Protocol (EPP) for the registration and management of Internet infrastructure data, including domain names. He has contributed to several industry efforts including internationalized domain names, ENUM, public key cryptography, S/MIME, the Extensible Markup Language (XML), and the Transport Layer Security (TLS) protocol. He has served as a member of the Internet Engineering Steering Group of IETF.
Elisa Kendall has over 30 years of experience in the design and deployment of enterprise-scale information management systems in financial services, government, manufacturing, media, and travel domains. She represents ontology and information architecture concerns on the Object Management Group (OMG)’s Architecture Board, is co-editor of the Ontology Definition Metamodel (ODM), and a contributor OMG’s Financial Industry Business Ontology (FIBO) effort. She has participated in the ISO JTC1 SC32 WG2 Metadata working group and was a member of the W3C OWL and Best Practices working groups.
Doug Migliori has over 20 years of experience in supply chain and retail automation systems and mobile application development platforms. He has contributed to several open source consortia solving interoperability challenges including GS1, ARTS, OMG, CABA, IPSO Alliance, and OCF. Doug administers the IoT in Retail, IoT in Healthcare, and IoT in Homes and Buildings LinkedIn Groups. He is a principal with ControlBEAM, which provides a Unified Commerce platform built on the BEAM common data service.
John Petze is a partner at SkyFoundry, the developers of SkySpark, an analytics platform for building, energy, and equipment data. John has over 30 years of experience in building automation, energy management and M2M/IoT, having served in senior level positions for manufacturers of hardware and software products including: President & CEO of Tridium, VP Product Development for Andover Controls, and Global Director of Sales for Cisco Systems Smart and Connected Buildings group, and is a member of the Association of Energy Engineers. He is the Executive Director of Project-Haystack.org.
J. Clarke Stevens is Principal Architect of emerging technologies at Shaw Communications. In this role, he analyzes emerging technologies and works with senior executives to develop product strategy. He is a public speaker on the IoT and an active technical contributor to the Open Connectivity Foundation (OCF). He has occasionally been a judge for the CES Innovation Awards. Clarke served on the board of directors of Universal Plug-n-Play Forum (UPnP), chaired the Technical Committee, and led the Internet of Things task force until UPnP was acquired by OCF.
References:
15. Vernon, Vaughn, Implementing Domain-Driven Design, Addison-Wesley, 2013
16. Murdock, Paul, Davies, John, et al., "Semantic Interoperability for the Web of Things", ResearchGate, Aug 2016
17. Hambley, Lee, "Blockchain or Event Sourcing", July 2017
18. Richardson, Chris, http://microservices.io
19. Byers, Charles., Swanson, Robert, et al., OpenFog Reference Architecture, OpenFog Consortium, Feb 2017




