
Low power solutions for always-on, always-aware voice command systems, part 2
May 15, 2018
Story

Recent advances in hardware and software have made it possible for compact, battery-powered products to include always-on voice command systems.
This is part two of a three part series. Read part one here.
Recent advances in hardware and software have made it possible for compact, battery-powered products to include always-on voice command systems, which have already proven their reliability and appeal in tens of millions of smart speakers. This paper describes new applications, techniques, hardware, and software that will make these products possible.
Hardware considerations for voice command in portable products
The core of the hardware for a voice command interface consists of a microphone array and a processor that can receive and interpret the audio signals from the microphones. Depending on the type of device, various other components may be needed, such as a wireless interface for Bluetooth Low Energy or WiFi, plus speakers, amplifiers, LEDs and displays to provide user feedback.
Microphone array design
Although it is possible to use a single microphone in a voice command product, most such products use a beamforming array of two to seven microphones. The array allows the audio processor to focus the pickup pattern of the microphones on the user’s voice, thus improving the signal-to-noise ratio of the user’s voice relative to the surrounding environmental noise. Research by DSP Concepts has shown that achieving the best possible signal-to-noise ratio is critical to the accuracy and reliability of a voice command product. However, the demands placed by the form factors of portable and battery-powered products present many challenges not present in products designed for home use.
Number of microphones: The DSP Concepts white paper “Designing Optimized Microphone Beamformers” demonstrates that increasing the number of microphones improves voice UI reliability, with an array of five microphones in a ring spaced 71mm apart delivering the best balance of performance and cost. The more closely the sensitivity of the microphones is matched, the better the performance of the beamformer; the most practical way to achieve this is to balance the microphone sensitivity in the hardware after the microphones are installed, so the sensitivity adjustment will compensate not only for the differing gain of the mics (which are typically specified to a precision of ±3 dB) but also for the acoustical effects of the enclosure on the microphones.
However, few portable products and almost no wearables have the space for such an array; true wireless earphones, for example, typically have room for only two mics in each earpiece. Also, the processing power required for such an array may be beyond the capabilities of the relatively small processors used in most portable devices. Therefore, software algorithms that perform beamforming and other voice UI optimization functions must have the capability of being optimized for two or at most three microphones.
Microphone selection: Because voice command products use multiple microphones, the two primary factors in microphone selection for these products will usually be size and cost. However, in portable and battery-powered products, the power consumption of the microphones also becomes important. MEMS microphones are already the standard in voice command products, and their small size, low cost and low power consumption makes their use even more critical in portable and battery-powered products. An additional benefit of piezoelectric MEMS microphones is that they are exceptionally stable and the sensitivity does not shift during solder reflow, humidity or with changes in temperature.
These microphones can feature analog or digital output, but analog microphones have typically been a better choice for ultra-low-power applications. Analog mics have an internal amplifier and thus need some power, but with PDM or I2S digital output have more internal components and thus draw more power. However, analog microphones may require adding an analog-to-digital converter stage, if this function is not already built into the SoC.
One example of a MEMS mic designed for ultra-low-power applications is the Vesper VM1010, an analog-output microphone rated to draw only 8 µA of power when in “Wake on Sound” mode. Considering that batteries in portable products typically dissipate about 50 µA of power even when fully powered off, the VM1010 has essentially zero effect on the battery life of a portable product.
A piezoelectric microphone element in the VM1010 is monitored by a very low-power comparator circuit, which sends a wake signal to the rest of the system when the sound at the mic exceeds a certain threshold, which is set by an external resistor. Proper choice of resistor sets the required threshold to optimize VM1010 for best performance in a variety of noise environments. The VM1010 focuses on sounds between 250 Hz and 6 kHz, for better pickup of human voices and rejection of environmental noises such as machinery rumbles and wind noise. The Zero Power listening in VM1010, therefore offers an ultra-low power mode before the lowest power voice activity detect mode in a system, thereby offering considerable power savings in standby. A single microphone of this sort can be used to trigger the microphone array, audio processing circuitry and Internet connection (if applicable) of a voice command product.
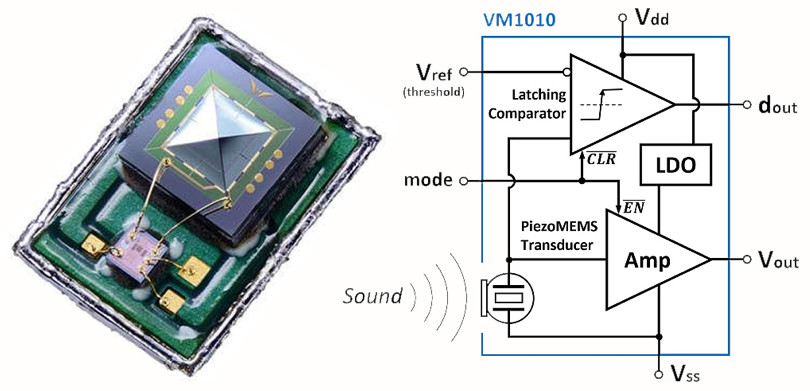
[Figure 1 | The Vesper VM1010 MEMS microphone (left) and its internal circuit configuration (right)]
Voice-recognition microphones in portable products must also be rugged, able to withstand the shock of the product being dropped from waist-high onto concrete. They may also need to be waterproof or at least water-resistant. The VM1010 cited above is immersible, dustproof and shockproof, so it meets all of these criteria.
According to testing conducted by DSP Concepts (presented in the white paper “Designing Optimized Microphone Beamformers”), the signal-to-noise ratio of the microphones in an array is not critical. Using microphones with tighter sensitivity tolerances can help performance—the paper details the improvements made by using microphones with ±1 dB tolerance rather than the more typical ±3 dB. However, considering that each microphone in an array may be in a different acoustical environment, due to the physical design of the housing, it is best to match the microphone sensitivity in the processor rather than in the microphones themselves.
Another possible way to save power is by using an accelerometer to wake the device, so an abrupt movement can activate the microphone array and processing circuitry. This design can eliminate the need to have a microphone always “listening.” It is probably not practical in products such as remotes and control panels, which may lie beyond arm’s reach, but it may be practical in some wearables.
Audio processor considerations
In any voice-command product, the audio processor—whether a dedicated DSP or a processing core within an SoC—must have the necessary computational capability to process the signals from all of the microphones in an array, and to run all the algorithms necessary for voice recognition. The more advanced algorithms and the more microphones the chip can accommodate, the better the signal-to-noise ratio and more accurate the voice recognition will be. In portable and battery-powered products, however, the processor must also consume as little power as possible in order to maintain adequate battery life in the product. This delicate balancing act of computational and power efficiency is an extremely difficult engineering challenge.
One processor line designed specifically to handle substantial audio processing tasks in products with small form factors and battery power is Ambiq Micro’s Apollo line. These microcontrollers and SoCs are designed using Ambiq Micro’s SPOT (Subthreshold Power Optimized Technology) platform, which allows them to run on less than 1/10th the current of a typical audio processor. The company’s first SPOT-based MCU, the Apollo1, is a 24 MHz Cortex M4F-based MCU focused on sensor processing. It consumes 35uA/MHz with the processor at full load and as little as 143 nA in sleep mode, only about 0.003x the typical quiescent power dissipation of the batteries used in portable products.
The next generation Cortex M4-based Apollo2 adds PDM inputs along with a doubling of the memory footprint and processing capability to 48 MHz to focus on ultra-low power, always-on voice command processing. The Apollo2 Blue further builds on the Apollo2’s capabilities with an integrated Bluetooth low-energy controller and Bluetooth 5-ready radio.

[Figure 2 | Block diagram showing the structure and features of the Ambiq Micro Apollo2 Blue]
The Apollo2 and Apollo2 Blue processors are capable of processing signals from two- or three-microphone arrays today using DSP Concepts’ Voice UI algorithms (discussed below), making them appropriate for ultra-low power hearable, wearable, and other mobile applications. Ambiq Micro is also planning to release the Apollo3 Blue, which will offer additional computational bandwidth to handle more microphones as well as even lower active power consumption and sleep modes—and thus achieve tighter beamforming patterns, better signal-to-noise ratios and better voice recognition accuracy.
All of these processors have the compact size needed for tiny wearable products such as earphones; they measure from 2.5mm to 4.5mm square, depending on the pin configuration. The Apollo1’s active power consumption is rated at 35 µA/MHz, while the Apollo2 and Apollo2 Blue are rated at less than 10 µA/MHz. With the Apollo2 Blue’s Bluetooth 5 radio, it can act as a dedicated Voice-over-Bluetooth Low Energy channel for voice assistants.
Additional components
Beyond the microphone array and audio processor, a voice command product will require additional components. Specific component requirements will depend on the application and form factor, but there are a few that almost every voice command product will employ. As with the microphones and processors, these components must be chosen not only for their functions and performance, but also for small size and low power consumption.
Wireless interface: In order to offer more than the most basic capabilities, voice command products need to access the Internet, so they can send and receive data from external servers. With smart speakers designed for home use, this connection is made through WiFi to a LAN. With portable voice-command products, it is typically made through Bluetooth to a smartphone or tablet, which is in turn connected to the Internet through a cellular data network or through WiFi.
User feedback components: Most voice command products incorporate some kind of user feedback, to confirm that the device is active, that it heard and understood the user’s command correctly, and that it will carry out the desired action. These devices can be LEDs, such as the flashing lights atop the Amazon Echo and Google Home smart speakers. They can also be alphanumeric or graphical displays, which may be found on many remotes and home automation wall panels.
Most of these devices will likely have audio feedback as well, which may confirm the user’s command through alert tones or through voice synthesis—yet another load placed on the processor. The unit must employ an amplifier and a speaker of some sort to reproduce the voice and/or alert tones. Some products may use multiple drivers with a beamforming algorithm to direct the response back at the listener.
Industrial design considerations
The physical design of a product can have a large impact on the performance of its voice recognition systems. As noted in the DSP Concepts white paper cited above, precise matching of microphone sensitivity is essential to reliable beamformer performance and accurate voice recognition.
If the microphones in an array are placed at different distances from the edge of a product, for example, they will have a different frequency response and thus differing sensitivity at different frequencies. The consistency of the microphone mounting is also an issue; the microphones must, to the greatest extent possible, be installed in exactly the same fashion to minimize any acoustical differences that could arise from inconsistent mounting. Any seals around the microphones must also be consistent in design, materials and installation.
Besides taking care to design voice command products so every microphone in their arrays is in a similar acoustical environment, manufacturers can assure best possible performance of voice command products by level-matching the microphones of each unit individually at the factory. This extra QC step assures that differences in microphone performance due to minor manufacturing inconsistencies do not affect the accuracy of voice recognition.



