
Keeping complexity in check with embedded code generators
July 24, 2017
Blog

Raspberry Pi and today's MCUs have much in common as they seek to reduce complexity for developers. Though their intricacies can become a challenge, modern embedded code generators can help.
The Raspberry Pi lineup was expanded in February 2017 with the Raspberry Pi Zero W[1], a $10 personal computer with wireless connectivity. What a wonderful time this is for hobbyists, makers, tinkerers, hackers, and, yes, the few of us who are actually trying to do our job designing “real” electronic products!
While slight differences arise given Raspberry Pi’s “general computing” distinction and the “embedded” classification of microcontrollers (MCUs), both share the common goals of “keeping complexity under control” for developers while “attracting novice users.” Free software tools including integrated development environments (IDEs), compilers, linkers, simulators, debuggers, and more-or-less open middleware and operating systems (OSs) are available on each type of platform. Both rely heavily on similar, if not identical, GNU-based toolchains. At the middleware level, the open source options are again very similar once the lower (down to the metal) driver layers are abstracted.
Despite their mission of supporting developers by reducing complexity, however, the problem of documentation inflation is apparent on both sides. A perfect example is that of a small 8-bit MCU based on the PIC architecture, the PIC16F1619. The PIC16F1619 MCU is used to control small appliances and, to this end, packs only 16 kB flash in a 20-pin package, 12 digital peripheral interfaces, and about as many analog support modules, yet its datasheet spans 650 pages (before adding in characterization data, charts, and graphs)[2]. Peripherals offered on the PIC16F1619 (such as the Signal Measurement Timer (SMT)) require as many as 50 of those pages, which is almost twice the number of pages required to describe the actual PIC core and its entire instruction set.
Issues are similar on the Raspberry Pi side, only magnified proportionally (as much as 10x). There are several datasheets to consider here, each of which documents only one component of the system on chip (SoC) such as peripherals, GPU, etc.. The core alone takes up more than 750 pages.
Nobody can be expected to read or simply keep up with such vast amounts of information. Embedded developers in particular are always under extreme pressure to deliver applications in ever-shorter time frames to achieve the fastest time-to-market.
Lost in the layers of embedded software architectures
One common solution to the deluge of information is to partition applications using a layered architecture with standardized peripheral libraries that abstract hardware details. The layers can be represented as a neatly formed stack, with the “application” sitting on top of a hardware abstraction layer (HAL). The stack can be further refined to identify the HAL and a middleware layer on top of it that implements common services/functions such as networking, file systems, and graphical user interfaces (GUIs), if required (Figure 1).

[Figure 1 | Shown here is a representation of an embedded application’s software stack, which can be refined further by separating out the driver and board support layers.]
This software architecture model is derived from the “computing” world and works well in most generic cases. Unfortunately it suffers from two fundamental shortcomings in embedded applications:
1. The layered architecture simplifies documentation inflation problem as long as the focus is on the standard functions provided by the middleware layer. At the lower end of the application spectrum, where middleware layers are very thin if present at all, the result is mostly obfuscation. Developers must therefore rely on HAL documentation in the form of a large application programming interface (API), which is an equally large body of material that can span several thousand pages without ever truly revealing the specifics of a device. When problems arise, the developer is left in limbo or forced to dive deep into a large body of foreign code.
2. The HAL layer provides a tremendous support for standard middleware services, but because of its rigid nature often ends up erasing unique differentiating features of a specific device. Those features could otherwise provide technical advantages to a particular application, and may have been the very reason a specific device was selected in the first place.
Code generators: Let the machine do what it does best!
As performance penalties are incurred and unique features are flattened by the stacked software architecture, modern MCU developers receive diminished benefits when working with a standardized HAL. However, a new generation of code generators for the embedded control market that emphasizes rapid development offers a way out of this conundrum.
Code configurators/generators do what machines do best, significantly shortening or eliminating the repetitive and error-prone process of scouring datasheets to configure hardware peripherals and build HALs. Users can also learn about specific hardware peripheral capabilities from a single code configurator interface, reducing the need for datasheets altogether. As a result, HALs become a flexible part of an embedded development project that can be regenerated quickly and frequently as engineers optimize application performance.
Among the distinguishing features of code configurator tools are:
· Full integration with popular IDEs, allowing the tool (and user) to remain aware of the project context (model/part numbers involved, middleware libraries in use, etc.)
· Support for unique and complex peripherals, such as the SMT mentioned earlier. For example, the SMT can be visually presented to the user in a single page/dialog box that includes a handful of intuitive scrolling lists and check boxes (Figure 2).
· A templating engine that translates user configurations into a small set of fully customized functions, reducing the number of parameters that must be passed to each function and guaranteeing that most hardware abstraction is performed statically at compile time. The resulting API is minimal with few functions to learn, and leverages consistent and intuitive naming conventions. This increases performance and code density (Code Sample 1).
· An output composed of very short (C language) source files that can be completely inspected by the user, providing the opportunity to learn and manually optimize. Modern code configurators mix generated code with user code in an agile manner that preserves integrity and allows advanced hardware features to be fully exploited.
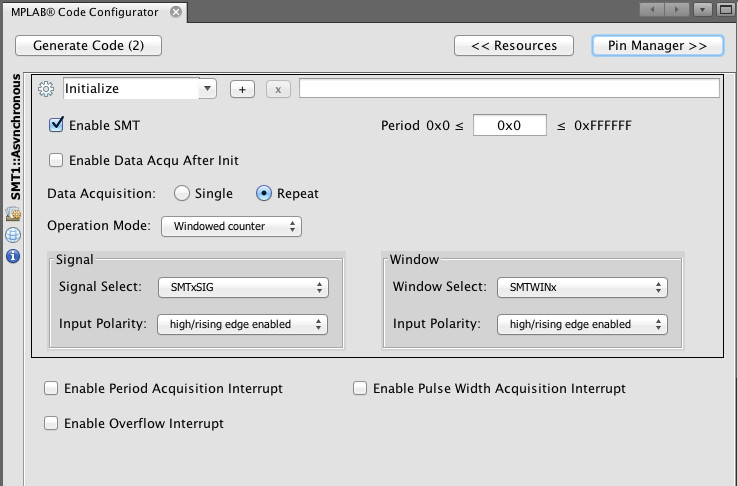
[Figure 2 | Shown here is a screenshot of options for the Signal Measurement Timer (SMT) within Microchip Technology, Inc.’s MPLAB Code Configurator (MCC).[4]]

[Code Sample 1 | This sample section of the SMT peripheral source file (smt1.c) shows the frugality of code generated by MCC.]
Once peripheral configuration is complete, developers can immediately focus on the application. Using a code generator, the classic embedded “Hello, World!” example (invariably translated into a blinking LED) becomes a two-line-of-code exercise.

[Code Sample 2 | The only two lines of code needed to create a “Hello, World!” application using MCC.]
20 other practical examples of the effective use of rapid development tools can be found in the book, “In 10 Lines of Code”[5].
Fighting complexity
As I watched Eben Upton’s video announcement on the Pi Zero W, I couldn’t help but reminisce about my early years. Back then it was the mid 80s. I couldn’t afford a BBC computer or the luxurious Amiga, but I did spend all my money on a Sinclair ZX Spectrum. Eben’s efforts to make computing “affordable for all” really resonate with me.
I continue to be amazed by the record low price points reached by what is, after all, a powerful PC squeezed into a tiny 6 cm x 3 cm printed circuit board (PCB). I often wonder whether it was precisely the frugality and many limitations of the Spectrum that taught me to dig deeper into electronics and made me fall in love with that strange world of machines – that frontier between software and hardware that today we call embedded.
As little MCUs grow into little system on chips (SoCs), or PCs shrink into Raspberry Pis, complexity does not have to be the inevitable consequence of technology advancement. Modern code configurators can help us augment our software development process and eventually restore our command of the rapidly growing number of features available.
Lucio Di Jasio is the EMEA Business Development Manager for Microchip Technology, Inc. As an opinionated and prolific technical author, Lucio has published numerous articles and several books on programming for embedded control applications. You can read more about Lucio's latest books and projects on his blog at: http://blog.flyingpic24.com
Microchip Technology, Inc.
LinkedIn: www.linkedin.com/company/microchip-technology
Facebook: www.facebook.com/microchiptechnology
Google+: https://plus.google.com/+MicrochipTech
YouTube: www.youtube.com/user/MicrochipTechnology
References:
1. The RaspberryPi ZeroW announcement. https://www.raspberrypi.org/blog/raspberry-pi-zero-w-joins-family/
2. PIC16F1619 datasheet. http://microchip.com/pic16f1619
3. Lines of code in the Linux kernel. https://arstechnica.com/business/2012/04/linux-kernel-in-2011-15-million-total-lines-of-code-and-microsoft-is-a-top-contributor/
4. MPLAB Code Configurator. http://microchip.com/mcc
5. In 10 Lines of Code. http://blog.flyingpic24.com/10lines



