
RapidIO: Optimized for low-latency processor connectivity
December 01, 2012

Interconnect architectures reflect the problems they are designed to solve. Focusing too heavily on raw bandwidth metrics often misses more important...
As Moore’s Law has continued to drive the performance and integration of processors, the need for higher-speed interconnects has continued to grow as well. Today’s interconnects commonly sport speeds ranging from 10 Gbps to 80 Gbps and have roadmaps leading to hundreds of gigabits per second.
In the race to faster and faster interconnect speeds, some topics are not often discussed, including the types of transactions supported, communications latency and overhead, and what sorts of topologies can be easily supported. Designers tend to think of all interconnects being created equal and having a figure of merit based solely on peak bandwidth.
Reality is quite different. Much as there are different forms of processors optimized for general-purpose, signal-processing, graphics, and communications applications, interconnects are also designed and optimized for different connectivity problems. An interconnect typically solves the problems it was designed for and can be pressed into service to address other applications, but it will be less efficient in these applications.
RapidIO design objectives
It is instructive to look at RapidIO in this context. RapidIO was designed to serve as a low-latency processor interconnect for use in embedded systems requiring high reliability, low latency, and deterministic operation. It was designed to connect different types of processors from different manufacturers in a single system. Because of this, RapidIO has found widespread use in wireless infrastructure equipment, where there is a need to combine general-purpose, digital signal, FPGA, and communication processors together in a tightly coupled system with low latency and high reliability.
The usage model of RapidIO required providing support for memory-to-memory transactions, including atomic read-modify-write operations. To meet these requirements, RapidIO provides Remote Direct Memory Access (RDMA), messaging, and signaling constructs that can be implemented without software intervention. For example, in a RapidIO system, a processor can issue a load or store transaction, or an integrated DMA engine can transfer data between two memory locations. These operations are conducted across a RapidIO fabric, where their sources or destination addresses are located, and typically occur without any software intervention. As viewed by the processor, they are no different than common memory transactions.
RapidIO was also designed to support peer-to-peer transactions. It was assumed multiple host or master processors would be in the system and that those processors needed to communicate with each other through shared memory, interrupts, and messages. Multiple processors (up to 16K) can be configured in a RapidIO network, each with their own complete address space.
RapidIO also provides a clean dividing line between the functionality of switches and endpoints. RapidIO switches only make switching decisions based on explicit source/destination address pairs and explicit priorities. This allows RapidIO endpoints to add new transaction types without requiring changes or enhancements to the switch devices.
Comparing interconnects
As more and more of the system is incorporated onto a single piece of silicon, PCI Express (PCIe) and Ethernet are being integrated within Systems-on-Chips (SoCs). This integration, however, has not changed the nature of the transactions provided by these interconnects (see Figure 1).
|
|
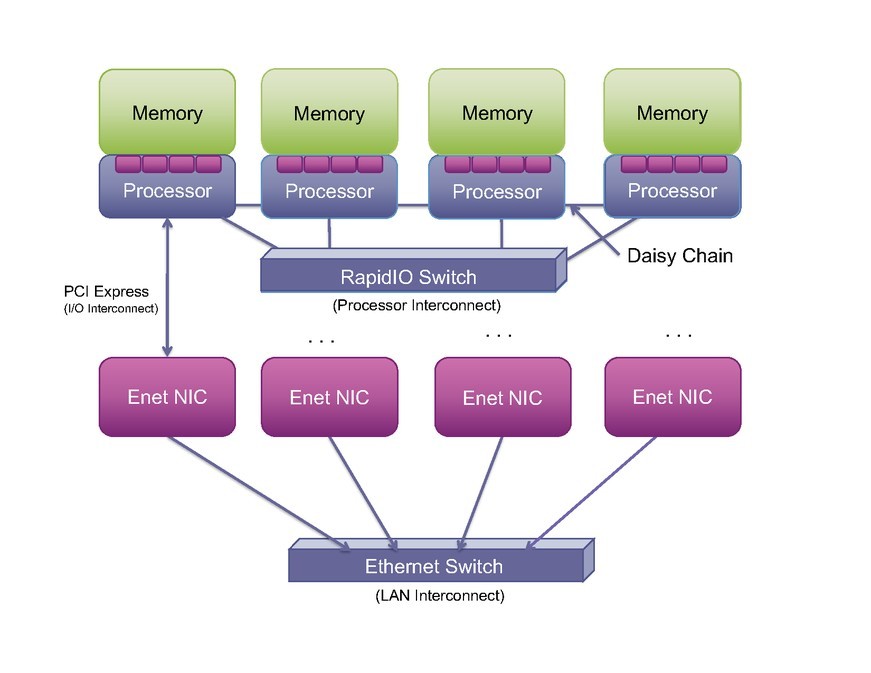
PCIe does not natively support peer-to-peer processor connectivity. Using PCIe for this sort of connectivity can be exceedingly complex because it was designed as a peripheral component interconnect (hence PCI). It was intended to connect peripheral devices, typically slave devices like I/O and graphics chips, to the main host processor. It was not designed as a processor interconnect, but rather as a serialized version of the PCI bus. Building a multiprocessor interconnect out of PCI requires a step beyond the base PCI specification to create new mechanisms that map address spaces and device identifiers among multiple host or root processors. To date, none of the proposed mechanisms to do this – Advanced Switching (AS), Non-Transparent Bridging (NTB), or Multi-Root – I/O Virtualization (MR-IOV) – have been commercially successful.
For systems where there is a clear single host device and other processors and accelerators operate as slave devices, PCIe is a good choice for connectivity. However, for connecting many processors together in more complex systems, PCIe has significant limitations in topology and support for peer-to-peer connectivity.
Many developers are looking to leverage Ethernet as a solution for connecting processors in systems. Ethernet has evolved significantly in the past 35 years. Similar to the increase in computer processing speeds, its peak bandwidth has grown steadily. Currently available Ethernet Network Interface Controller (NIC) cards can support 40 Gbps operating over four pairs of SERDES with 10 Gbps signaling. Such NIC cards contain significant processing on their own to be able to transmit and receive packets at these speeds.
The sending and receiving of Ethernet packets by a NIC is a long way from being a solution to tightly coupled interprocessor communications. The overhead associated with both PCIe and Ethernet transaction processing (both stacks must be traversed in a NIC), plus the associated SERDES functions and Ethernet media access protocol and switching add latency, complexity, and higher power dissipation as well as cost to systems where much more direct connection approaches could be utilized (see Table 1).
|
|

Using Ethernet as an integrated embedded processor interconnect requires significant transaction acceleration and enhancements to the Ethernet Media Access Controller (MAC) as well as the Ethernet switch devices themselves. Even with these enhancements, RDMA operations should be limited to large block transactions to amortize the overhead of using Ethernet.
Standards that have been deployed to solve this problem include the iWARP RDMA protocol from the Internet Engineering Task Force and RDMA over Converged Ethernet (RoCE). Both iWARP and RoCE are typically implemented through acceleration coprocessors. Despite this acceleration, RDMA transactions must still be carefully managed to reduce communications overhead. The reason is that although Ethernet offers high bandwidth, especially in 10 GbE and 40 GbE implementations, it also has high transaction latencies that are typically measured in microseconds.
Current RapidIO applications
The RapidIO value proposition has been widely acknowledged in the embedded market for many years. This same value proposition can now be extended to more mainstream data-processing markets, which are evolving to demand many of the same system attributes that communications networks have long required.
One well-known application wherein RapidIO is utilized is the wireless base station. This application combines multiple forms of processing (DSP, communications, and control) that must be completed within a very short time frame. Communications between processing devices should be as quick and deterministic as possible to ensure that real-time constraints are achieved.
For example, in 4G Long-Term Evolution (LTE) wireless networks, frames are sent every 10 milliseconds. These frames, which contain data for multiple concurrent mobile sessions, are distributed across multiple subcarriers, which are supported by multiple DSP devices. Communications between the DSP and general-purpose processing devices must be deterministic and low latency to ensure that a new frame is ready for transmission every 10 milliseconds. At the same time, the receive path must support the data arriving from the mobile devices connected to the network. On top of this complexity, the system must track the location of the mobile device in real time and manage the device’s signal power.
Another example of a RapidIO application is semiconductor wafer processing. Similar to the wireless infrastructure application, semiconductor wafer processing has real-time constraints, including a control loop of sensors, processing, and actuators. Leading-edge systems often have hundreds of sensors collecting information, with sensor data processed by tens to hundreds of processing nodes. The processing nodes generate commands that go to actuators and AC and DC motors to reposition the wafers and wafer imaging subsystems. This is all performed in a recurring control loop with a frequency of up to 100 kHz or 10 microseconds. Systems like this benefit from the lowest-latency communications possible between devices.
The future of high-performance computing
The introduction of virtualization, ARM-based servers, and highly integrated SoC devices is paving the way for the next stage in the evolution of high-performance computing. This evolution is moving toward more tightly coupled clusters of processors that represent processing farms built to host hundreds or thousands of virtual machines. These processor clusters will be composed of up to thousands of multicore SoC devices connected through high-performance, low-latency processor interconnects. The more efficient this interconnect is, the better the system’s performance and economics will be.
Technologies like PCIe and 10 GbE are not going away anytime soon, but they will not be the foundation for these future tightly coupled computing systems. PCIe is not a fabric and can only support the connectivity of small numbers of processors and/or peripherals. It can simply serve as a bridge to a fabric gateway device. While 10 GbE can be used as a fabric, it has significant hardware and software protocol processing requirements. Its widely variable frame sizes (46 B to 9,000 B for jumbo frames) drive the need for fast processing logic to support several small packets and large memory buffers to support large packets in endpoints and switches, thus hiking up silicon cost. The use of PCIe or 10 GbE will either restrict the topologies and connectivity available or add cost and overhead to the system. These drawbacks create opportunities both for proprietary fabrics and for open solutions such as RapidIO in this interesting new market.
Implementing integrated server, storage, and networking systems presents an opportunity for OEMs to innovate. A key component of that innovation will be the internal system connectivity. RapidIO is a mature, well-proven technology with the attributes required for success in this market. As was the case for wireless infrastructure, where RapidIO went from early innovation to become the de facto base station interconnect standard, RapidIO’s biggest challenge in server, storage, and high-performance computing will be to cross the chasm from today’s innovators and early adopter markets to mass-market proliferation.
RapidIO Trade Association [email protected] www.rapidio.org
Follow: RapidIOTA Facebook Google+




