
AI Compilers and the Race to the Bottom
November 05, 2020
Blog

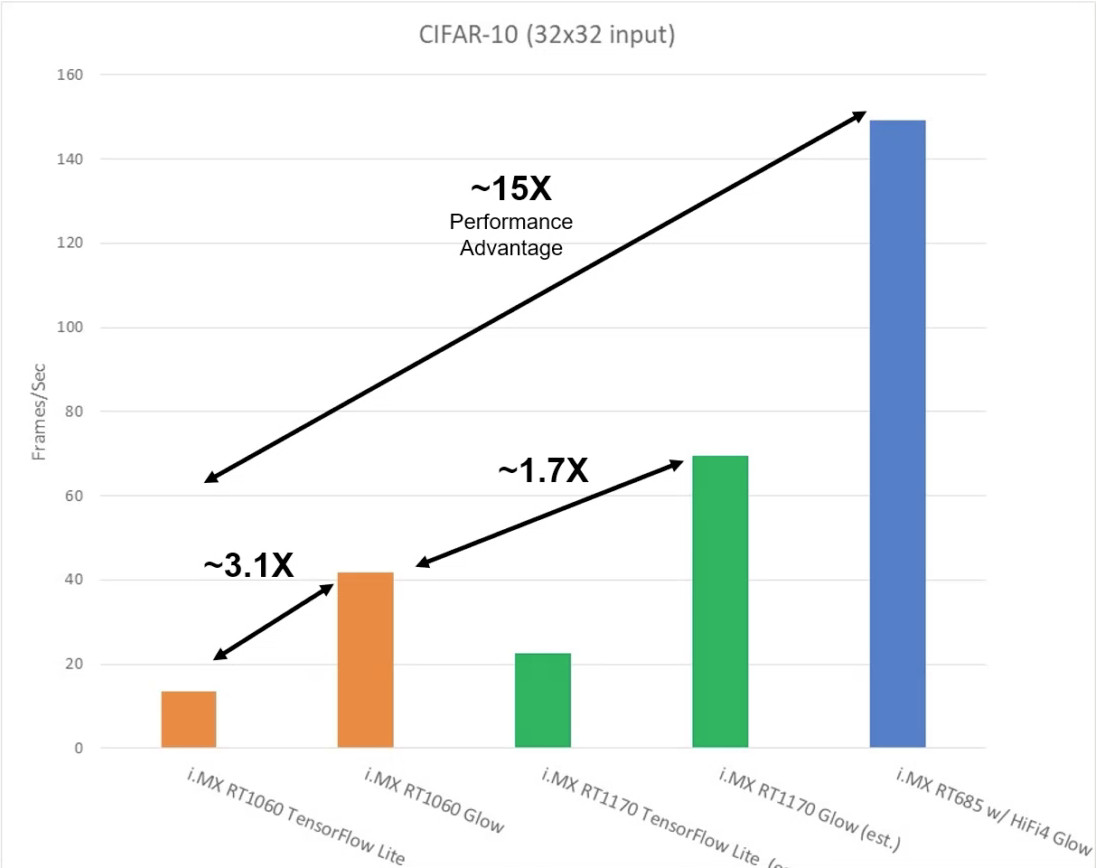
Glow-compiled inputs exhibited a 3x frames/second performance improvement over TensorFlow/TensorFlow Lite, while the figure gives an idea of how efficient AOT compilation is compared to JIT compilers.
Creating intelligence requires a lot of data. And all of that data needs technologies that can support it.
In the case of artificial intelligence (AI), these technologies include large amounts of direct-access, high-speed memory; parallel computing architectures that are capable of processing different parts of the same dataset simultaneously; and, somewhat surprisingly, lower-precision computing than many other applications. An almost endless supply of this technology mix is available in the data center.
AI development tools were therefore designed for the data center infrastructure behind applications like internet queries, voice search, and online facial recognition. But as AI technology advances, so does the desire to leverage it in all sorts of use cases – including those that run on small, resource-constrained, MCU-based platforms at the edge. So instead of focusing solely on high-end hardware accelerators running cloud-based recommendation systems, for example, tools like compilers must also be able to optimize AI data and algorithms for smaller footprint devices.
Facebook’s open-source machine learning compiler, Glow, is an example of this tooling evolution. It “lowers” neural network graphs using a two-phase intermediate representation (IR), which generates machine code that is specially-tuned to the features and memory of a variety of embedded and server-class hardware targets (Figure 1). It also performs ahead-of-time (AOT) compilation, which minimizes runtime overhead to save disk space, memory, startup times, and so on.
“We have this really high-performance runtime, but a lot of projects don’t care because they aren’t in the data center,” explained Jordan Fix, a research scientist at Facebook. “They need to do AOT compilation, shrink as much as they can, use quantization and parallelization, and not have a lot of dependencies.
“AOT compilation isn’t as important in the data center, but we can hook LLVM back ends into Glow and target x86, Arm, RISC-V, and specialized architectures,” Fix continued. “The way Glow works is you have a couple levels of IR that use high-level optimizations and quantizations to limit memory. At that point the compiler back end can accept the instruction-based IR and optimize and compile it down however it wants.”
Another big advantage of Glow, especially in the diverse embedded technology landscape, is the ability to compile models within a simple C wrapper. This means embedded AI engineers can optimize Glow for their compiler backend and architecture of choice. It natively supports inputs from popular AI frameworks and libraries such as PyTorch and Arm’s CMSIS-NN, and can also accept graphs from environments like TensorFlow via the ONNX neural network exchange.
AI Compilers’ Race to the Bottom
Of course, Glow is not the only neural network compiler available. Google’s Multi-Level Intermediate Representation (MLIR) is a compiler infrastructure that focuses on tensor processors and has been absorbed by LLVM. Microsoft’s Embedded Learning Library (ELL) is another cross-compiling toolchain for resource-constrained AI devices.
However, Glow is more mature than either, having been open sourced in 2018. It’s also more performant than many existing AI compiler options.
In performance tests on their recently released i.MX crossover MCUs, NXP systems engineers compiled 32 x 32 CIFAR-10 datasets using TensorFlow Lite and Glow and fed them into RT1060, RT1170, and RT685 devices. Glow-compiled inputs exhibited at least a 3x frames/second performance improvement, while Figure 2 gives you an idea of just how efficient AOT compilation is compared to the just-in-time (JIT) compilation used in the TensorFlow/TensorFlow Lite frameworks.
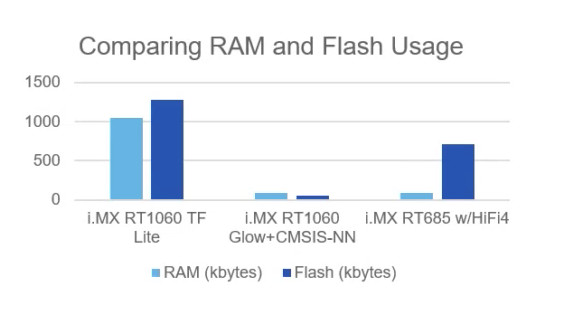
Keep in mind, the i.MX1060 has up to 1 MB of on-chip RAM. NXP’s eIQ software development environment supports Glow.
Open-Source AI: No Finish Line in Sight
The AI technology market is changing rapidly, which makes it difficult for development organizations to commit to any technology. This may be one of the most compelling aspects of Glow, and it isn’t even directly related to technology.
As an open source project with more than 130 active contributors, large organizations like Facebook, Intel, and others continue making commits to the Glow mainline because they now depend on its common infrastructure for access to instructions, operators, kernels, etc.
And then, obviously, there’s the inherent value of open source.
“We regularly see contributions from external users that we care about like a more generic parallelization framework, and we have a lot of machine learning models that they are running,” Fix said. “So maybe it allows them to get support for operators without us having to do anything. ‘I think you were working on this specific computer vision model’ or, ‘I think this was an operator that you were talking about.’ They just review it and port it and land it.
“We can all benefit from each other’s work in a traditional open source framework,” he added.
For more information on the Glow machine learning compiler, visit ai.facebook.com/tools/glow or github.com/pytorch/glow.
For more on the NXP eIQ environment, visit nxp.com/design/software/development-software/eiq-ml-development-environment/eiq-for-glow-neural-network-compiler:eIQ-Glow.



