
Current and Future Challenges in IoT Development Silos, Part 1
February 27, 2020
Story
In this first part of a two-part article series, we discuss the challenges of modern, distributed, Internet of Things and Data of Things application development, deployment, and ongoing support.
In this first part of a two-part article series, we discuss the challenges of modern, distributed, Internet of Things and Data of Things application development, deployment, and ongoing support. Specifically addressed are the challenges of development across what we refer to as technology “silos,” as well as the challenges of secure and reliable deployment across cloud, fog, and edge compute nodes for modern application needs.
As the Internet of Things market matures, this article contemplates the emergence of a network-spanning abstraction layer and compute model. These could enable application and system development from a single unifying programmer perspective across a network of heterogeneous computational endpoints and communication layers.
With the rapid rise of the IoT, and the increased production and diversity of IoT devices, we've seen innovative technologies greatly improve productivity and/or generate whole new business models. At the same time, modern embedded and IoT solutions are distributed and heterogeneous, with hardware targets comprising low-power 8-bit MCUs, lightweight but powerful network gateways, and the near limitless resources of internet cloud servers.
Modern IoT solutions require expertise across disparate development platforms, or “silos.” We use the term silos to represent the segmented development and deployment processes and tools required to bring a network-spanning IoT solution to fruition. As development moves from the cloud to embedded components within a system, increasingly specialized and costly talent is required that remains locked within a given development silo. This is because developing efficient, secure, and reliable embedded software still requires highly-specialized knowledge that comes with a steep, and often costly, learning curve.
All too often, the high-level abstractions that cloud and application developers take for granted have not found their way to embedded development. To wit, it is difficult if not impossible to stay agile while developing and deploying features across multiple teams, tools, and targets – logistical challenges slow the pace of product implementation and innovation.
A real-world embodiment of the problem could be a modern drone platform, comprising cloud servers for data collection, high-performance network gateways, as well as local on-device networking. In addition, the drone itself may be comprised of a robust applications processor likely running Linux or another operating system, various baremetal 8-bit MCUs handling functions such as brushless motor control, as well as various GPUs, cameras, and hardware accelerators with varying levels of programmability.
Many industry players have begun to recognize this rapidly growing problem, such as Intel Corporation, who recently stated, “One key difference between embedded and IoT is connectivity. We’re transitioning away from isolated devices into a group of connected devices with awareness of their surroundings.
“If you think about all the accelerators to do analytics – CPU, graphics, video accelerator, deep learning engine, FPGA – you're talking about 4-5 different programming environment. It’s not the same old tools environment. Tools must be done in a way that allows developers to move the workload and acceleration across all these accelerators in the cloud, gateway, and device as seamlessly as possible.”1
IOT AND DATA OF THINGS
Some might say the revolution of IoT can also be considered as being driven by DoT, or Data of Things. As such, an efficient and economical infrastructure of gathering, filtering, normalizing, processing, and storing data should be at the center of any IoT deployment.
For many businesses, cloud has become the primary choice for analyzing, storing, and visualizing the IoT data. However, for the obvious reasons like latency, availability, cost, and privacy, most people would agree that certain processing needs to be done close to the data sources (i.e. the IoT devices), which encompasses edge and fog computing. The result is that, in many cases, building, deploying, and supporting an end-to-end IoT data pipeline is a balancing act of deciding what should be done in the cloud and what should be at the edge or elsewhere, spanning multiple development targets, ecosystems, and developer resources.
This is due, in part, to the fact that deployment in the cloud is well understood, especially as cloud vendors like AWS have made large-scale data analysis and rendering increasingly foolproof with various tools and services. How to best build, deploy, and support data-driven computing infrastructure at the edge remains a best-effort practice for most businesses with little guidance or misguided principles. This has to do, in part, with the heterogeneous nature of IoT systems, which can be vastly different in hardware and software architecture, software packaging, and security capabilities.
Of similar importance and a big missing piece in the field today is a data-centric edge computing infrastructure. Such infrastructure needs to be able to:
? Standardize how IoT data is ingested and normalized
? Provide a systematic approach to divide and distribute data-processing workloads
? Automatically scale data processing tasks to accommodate a wide spectrum of data complexity and volume
? Simplify how AI/ML inferencing functions are built and deployed to the edge
DEVELOPMENT AND DEPLOYMENT CHALLENGES
There've been some pocket solutions in the market addressing one or two of these challenges. For instance, the AWS Greengrass service allows you to run microservices (in the form of Lambda functions) on embedded edge gateways; Azure IoT edge offers something similar except in the form of explicitly containerized apps.
At the time of this writing, however, these services comprise an oversimplified model of IoT and edge deployment, and currently fail to enable sophisticated data processing capability over a large network of IoT edge devices before sending the aggregated data to the cloud.
This is, in part, due to the fact that sophisticated, agile development approaches to building secure cloud-backed web applications have been strongly embraced by these developers, whilst the embedded world has largely fallen behind. The high-level abstractions that cloud and application developers take for granted have largely not found their way to embedded development, oftentimes making it the slowest most painful aspect of developing a complete solution.
A recent publication from O’Reilly summarizes aspects of this challenge quite nicely. The article Rethinking Programming states, “The programming world will increasingly be split between highly trained professionals and people who don’t have a deep background but have a lot of experience building things. The former group builds tools, frameworks, languages and platforms; the latter group connects things and builds websites, mobile apps, and the like.”2
As such, we must not only address the development challenges across various silos in the system architecture (cloud, fog, device/embedded), but also how to facilitate the builders deploying, configuring, reconfiguring, and supporting these robust systems in a pragmatic way that doesn’t require in-depth understanding of underlying hardware architectures and the like.
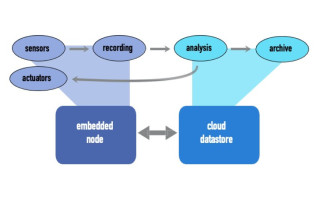
Consider, for example, the deployment of an application that comprises the architecture in Figure 1. The embedded node may be a low power 8-, 16-, or 32-bit MCU or DSP target that demands intimate knowledge of the underlying hardware architecture and, often, a firm grasp of the C programming language. The device may interface with various actuators, sensors, and serial communications protocols such as I2C, UART, and the like.

Figure 1. Example of an embedded device communicating directly with cloud compute.
Conversely, the cloud datastore on the right side of Figure 1 is often a highly provisioned multicore server with gigabytes of memory, perhaps running robust virtualized operating systems and executing applications built in abstracted frameworks with higher-level programming languages.
The cloud store may perform data logging, event processing, and similar functions.
As one would expect, programming the logic for each device requires varying levels of knowledge of the underlying architecture (or in the case of the cloud device, perhaps no knowledge at all), using vastly different frameworks, programming languages, and levels of operating system support (or no operating system at all, in the case of the embedded node).
Now consider the same application, but deployed on the architecture illustrated in Figure 2. While the architecture still comprises embedded and cloud nodes, a fog gateway is incorporated for recording, analysis, inference, or other logic. This node may be a well provisioned multicore Linux architecture that is programmable in C++ and the like.
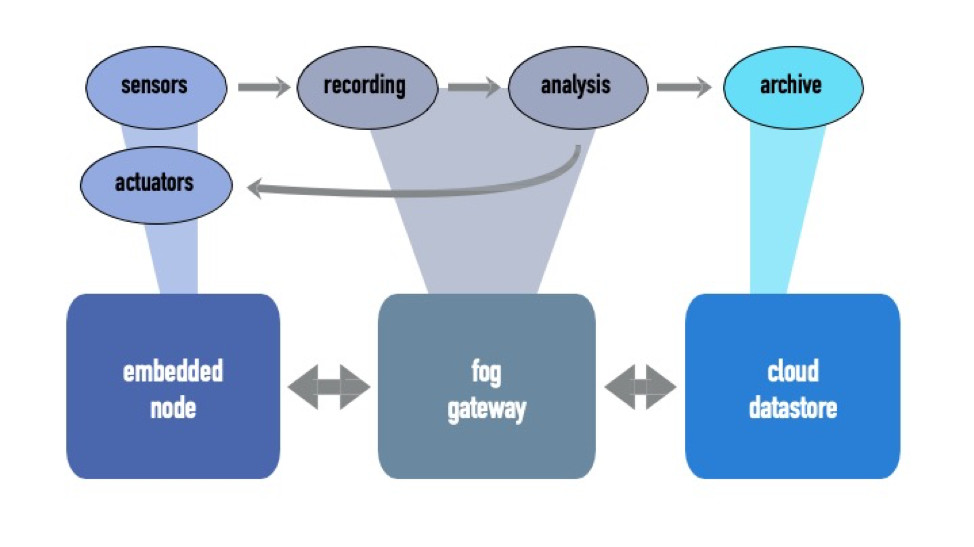
Figure 2. Example of an embedded device communicating incorporating fog with cloud compute.
This of course raises many questions:
- How is the existing application to be migrated across this evolving architecture?
- What if there are multiple embedded nodes and/or multiple fog nodes?
- What is a systematic way to migrate the application across the varying hardware targets, comprising varying levels of compute resources, operating system support, bandwidth, and connectivity?
- Moreover, one must also consider supporting security from the ground up, varying types of communication links, and development paradigms.
Clearly, the problem of development, deployment, and ongoing support quickly becomes intractable across the siloed architecture, as well as within the siloed development and deployment teams in an organization!
LOOKING FORWARD
With the future of IoT and DoT applications requiring embedded computing, fog computing, and cloud computing operating in concert, program managers and developers alike must be mindful of the human resources and capital required for building and deploying these solutions.
High-level cloud developers likely do not likely possess the intricate knowledge of embedded hardware, and many times do not possess the system-level understanding and programming skills required for these systems. Similarly, embedded developers more than likely are not aware of the high-level development frameworks and tools rapidly emerging for cloud development.
Care must be taken to align the many moving parts for unified and heterogeneous development, deployment, and ongoing support of these systems.
At the same time, however, the integration of silos goes far beyond just the development of a given target node. Various communications channels between devices must be accounted for, as well as the maintenance of infrastructure against which a given IoT application is deployed. In addition, the deployment of security configuration information and the security layers themselves must be continuously maintained throughout the lifecycle of an application’s deployment. When the application code, security layers, or configurations for one compute node within an internet of things application are updated, it need not only be tested and validated against the other software and systems enabling the application, but also be deployed in tandem. This iterative deployment cycle, often comprised of multiple interconnected software modules and layers (some proprietary and some third-party or open source, mind you) must be accounted for across development teams and enterprises.
In Part 2 of this article, we address specific development challenges across the silos of a given IoT deployment. We then further delve into potential future-facing solutions that facilitate the building of these types of silo-spanning systems, contemplating language and deployment scenarios within a given organization.
________________________________________________________________________________________________________
As always, Network Native is seeking like-minded individuals and interested parties to further this dialog, and welcomes reader comments via [email protected].
REFERENCES
1. Schwaderer, Curt, Embedded Computing Design, Driving IoT Innovation Along a Roadmap of Hardware, Software and Tools, April, 2018.
2. Mike Loukides, O’Reilly Programming Newsletter, Rethinking Programming, January 2020.



