
What's next for mobile? Heterogeneous processing evolves
August 06, 2014

The Heterogeneous Systems Architecture (HSA) furnishes design strategies for the next generation of mobile SoCs.
Advancing applications are driving an evolution in mobile processing, as standard CPU configurations can no longer provide the necessary performance within the power and space constraints of tomorrow’s high-end mobile devices and tablets. Heterogeneous SoCs comprised of CPUs and GPUs or DSPs are now being employed to execute demanding workloads within mobile resource envelopes, but they are also difficult to optimize and increase programming complexity; the Heterogeneous Systems Architecture (HSA) defines a structured approach to this new generation of hardware, mitigating development challenges and maximizing performance.
Traditionally, we have thought of a mobile processor as being a CPU or a collection of CPUs in dual-, quad-, or even octa-core configuration. It is only a few years since a single CPU core was the norm, but now multi-core configurations are becoming more and more common.
The progressive addition of this homogeneous compute power has been driven by the increasing need for mobile phones and tablets to take on more and more complex tasks. As use cases evolve and the phone becomes ever more central to everyday life, the range and complexity of these tasks is increasing beyond the ability of a single CPU to keep up.
However, in addition to the CPU, the mobile SoC has always been equipped with multiple other compute units, including DSPs and GPUs. GPUs have evolved over the past five years from being fixed-function, graphics-only devices to become highly programmable compute engines suitable for many more general-purpose computing tasks. At the same time, a number of programming languages have become available to ease the task of writing non-graphics applications for these GPUs. As a result, these units are now being harnessed to share the workloads of the demanding new use cases.
So now we must think of a mobile processor not merely as the CPU embedded in an SoC, but as the sum total of all the cooperating compute units arranged as a heterogeneous system, where we define ‘heterogeneous’ as multiple compute units with different instruction sets and architectures cooperating on a single distributed application.
The motivation for this shift is that mobile processors, especially those used in handsets, face a serious problem that cannot be solved by the homogeneous approach of simply adding more CPU cores. While Symmetric Multiprocessing (SMP) programming on the CPU array is convenient, it is also inefficient and power-hungry, making it fundamentally unsuitable for general use at the required performance level within the extreme power constraints of a mobile processor. And, while switching between varying core sizes can be helpful, it is not a solution to the fundamental problem of reducing the total power consumed per arithmetic operation.
Evolving to heterogeneous architectures
A heterogeneous approach offers the possibility of providing compute engines that, for a wide range of tasks, are far more efficient and far more scalable than CPUs. The GPU is one such engine that is extremely good at crunching through very large numbers of repetitive parallel operations on large data sets in a power-efficient, scalable fashion. However, it is not good at single-threaded, branching code such as is found in higher level control programs; this is best left to the CPU. So the challenge then becomes one of partitioning an application to take advantage of the unique benefits of each of these compute elements and getting them to work together cooperatively in an effective manner (Figure 1).

The Heterogeneous Systems Architecture (HSA), which is being defined and standardized by the HSA Foundation, is designed to address the second part of this challenge in a structured fashion that is consistent across multiple vendors’ devices.
Key HSA features
HSA is not the first or only heterogeneous system; there are a number of programming languages already in existence that enable programmers to access non-CPU compute units. NVIDIA has CUDA for its proprietary GPUs, but of more interest to mobile there are also Google’s RenderScript compute and OpenCL invented by Apple and since donated to the open standards community.
These languages are helpful, but they leave it up to the application developer to implement key features such as scheduling and de-scheduling of tasks between compute elements, notification of completion, access to shared data structures, and system-wide data integrity. A simple example will illustrate some of the problems programmers face when attempting to distribute processing across the various system resources.
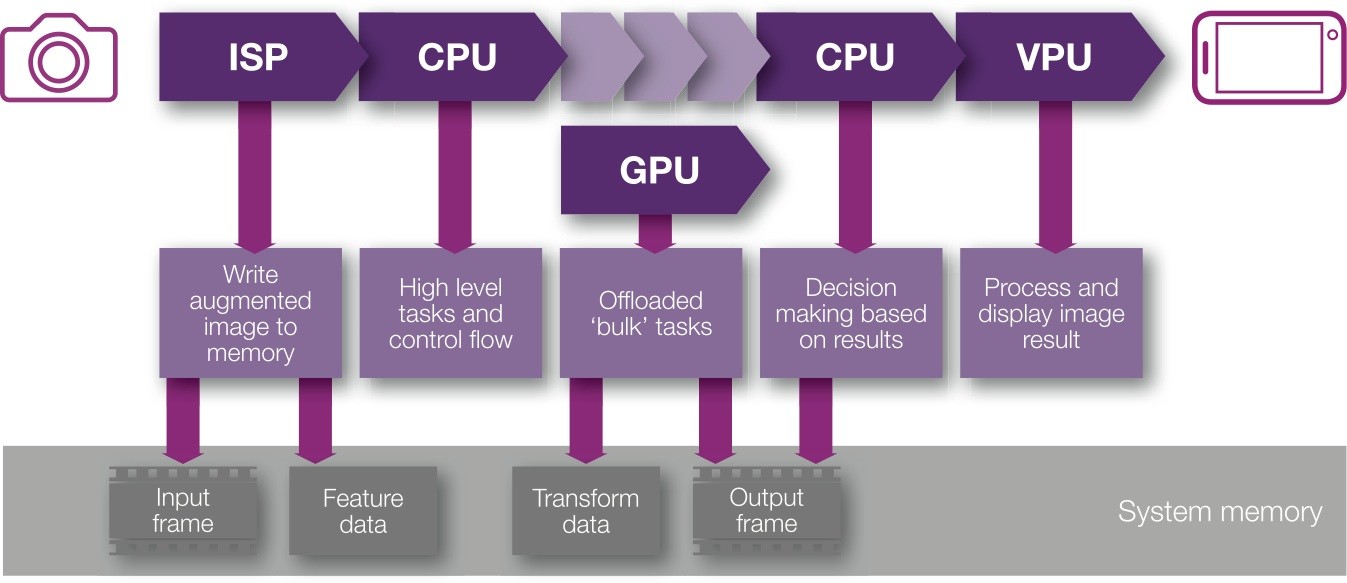
Let’s say an app wants to use an onboard sensor to capture a stream of images, and operate on them using the GPU before passing them to an encoder for compression into an H.265 video stream (Figure 2). Image data must be captured by the camera pipeline and buffered in memory before being handed off to the GPU for processing. Depending on the nature of the application, there may be a need to share data and results between the CPU and GPU before the modified image is buffered once again and finally passed to the encoder. Without some mechanism for all three units (CPU, GPU, and encoder) to share a common view of memory, either multiple copies of the image data must be created or sharing must be explicitly implemented by the application, with hardware-specific features coded into the software. Likewise, enqueuing tasks between CPU and GPU with all necessary synchronization and data coherency issues becomes an application-level, hardware-specific function.

Clearly, asking the majority of programmers to implement code with this level of hardware specific low-level functionality is not only impractical due to the difficulty of acquiring the necessary hardware knowledge, it is also undesirable because it complicates application portability. The need to become expert in a system before being able to program it efficiently also has the effect of restricting the heterogeneous programmer ecosystem to a very small minority. In addition, the need to explicitly synchronize data and task sharing between compute units results in very poor overall performance compared to a system that is capable of asynchronous operation and that implements task scheduling seamlessly in the background.
These are the items that HSA addresses in a systematic and standardized way, relieving the programmer of this burden and allowing hardware vendors to provide devices with far better heterogeneous performance through efficient hardware support.
Mobile-specific requirements
In the image capture example described previously, HSA uses Shared Virtual Memory (SVM) and user-defined queues to address the problems identified, so we can expect these features, along with many other HSA-defined features, to be supported in hardware for best performance (Figure 3). However, as with hardware support for any specific function there are associated power and area costs, so it is important to stay within the bounds needed in a mobile context by implementing only what is needed for the application space.
There are many applications suitable for heterogeneous computing and HSA sets out to cater to the entire range, from the High Performance Computing (HPC) end of the spectrum to apps that are appropriate for the mobile, consumer, and embedded markets. In order to do this efficiently, HSA has distinct profiles that exploit two key insights.
The first insight is that apps for the HPC and mobile markets have dissimilar requirements for things like floating point dynamic range, accuracy, and exception handling. The second is that, in general, there will be little to no crossover between the two markets: we will not see HPC apps migrate to the handset (although there might certainly be a migration in the opposite direction).
The applications driving mobile and consumer are almost exclusively visual: in automotive it is driver-assistance features like collision avoidance and navigation aids such as lane detection and street sign recognition; in television it is gesture recognition and viewer attention awareness; in mobile it is Human Machine Interface (HMI) features such as secure access and eye tracking for hands free operation. Digital still cameras already have extensive vision-based HMI features such as smile and blink detect using custom vision processors. In the future, these features will appear on mobile devices using the heterogeneous compute power of the onboard GPU.
Visual apps are an excellent fit for implementation on a GPU. The programmable compute cores on a typical GPU are explicitly designed to perform highly parallel operations on very large quantities of data using a small number of instruction counters. Taking the PowerVR GXT6650 as an example, 192 Arithmetic Logic Units (ALUs) are arranged in six clusters, each comprised of a pair of 16-wide SIMD units so that groups of 16 operations will be most optimal for execution. Low-level functions used by visual apps such as filter kernels or image-adjustment operations (hue and saturation controls, for instance) have the required level of parallelism and also only need small amounts of control code to run on the CPU, leading to a very efficient overall heterogeneous compute engine.
Another aspect of visual apps is that they typically have very relaxed floating-point requirements, if in fact they require any at all, (many do not) and the need for comprehensive exception handling and very high precision and rounding is absent. This, once again, fits very well with power-constrained mobile environments as such features are extremely power hungry. Thus, the ability to use the most power-efficient method helps significantly when writing apps to fit within an available power budget.
Hardware implications of HSA support
With the advent of heterogeneous mobile processors, and specifically HSA with its promise of support for high-level programming languages, developers will be able to access the compute performance they need without having to pay the penalty of the high power consumption that accompanies arrays of CPUs. This means we can expect to see a reversal of the trend towards multicore and a new short-term trend towards GPU hardware support, with more general heterogeneous computing in the longer term that will possibly incorporate general-purpose DSPs or specialized programmable engines in the vision pipeline, for instance. This is an important shift away from programming for a CPU architecture and towards programming for a system architecture, reinforcing trends already underway to reduce or eliminate the importance of CPU instruction sets.
As visual apps become more prevalent in mobile devices, expect to see hardware support tailored to application-specific requirements appear first in higher end processors, and then progressively in more mainstream devices.
Imagination Technologies Group




