
Platform and hardware requirements for HSA technologies
September 08, 2016
Blog
Heterogeneous system architecture (HSA) is now a standardized platform design, supported by more than 40 technology companies and 17 universities, tha...
Heterogeneous system architecture (HSA) is now a standardized platform design, supported by more than 40 technology companies and 17 universities, that unlocks the performance and power efficiency of the parallel computing engines found in most modern electronic devices. Spearheading HSA is the HSA Foundation, a non-profit consortium of SoC IP vendors, OEMs, Academia, SoC vendors, OSVs, and ISVs, whose goal is making programming for parallel computing easy and pervasive.
Briefly, HSA allows developers to easily and efficiently apply the hardware resources—including CPUs, GPUs, DSPs, FPGAs, fabrics, and fixed function accelerators—in today’s complex systems-on-chip (SoCs).
In this first of two posts, I’ll focus on platform and hardware requirements for HSA technologies; the second part will center on software and toolchains. Both will be discussed in depth at a tutorial at the upcoming 25th International Conference on Parallel Architectures and Compilation Architectures (PACT). The conference will be held from Sept. 11-15 in Haifa, Israel.
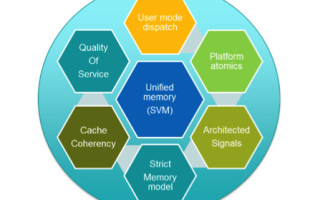
The architecture pillars of HSA
One of the key benefits of HSA is a set of platform architecture features and a programming model that software can depend on for parallel computing. Software using accelerators through an API like OpenCL, CUDA, or similar typically cannot assume that certain hardware features are available on every platform and so must either set a lowest common denominator or support many wildly different ways to essentially implement the same thing all over again to take advantage of an optional API feature while still supporting a lesser-equipped platform.

[Figure 1 | Pillars of HSA requirements]
HSA, in contrast, sets a requirement for a select few modern hardware features that make using the accelerator way more efficient and simplify the programming enormously, similar to what a CPU ISA like x86-64 or ARM has accomplished for compilers and application software development, with a reasonable expectation that a program will run efficiently on a platform with a particular processor and OS.
Let’s start with a brief list of requirements with a short explanation why they’re important.
Security and “quality of service”
An HSA accelerator is used as a peer processor to the CPU by the application, with all benefits and obligations. One of the key obligations is not allowing bad application code to do bad things to the system. Therefore, an HSA accelerator has a “user mode” ingrained for execution, where the operating system (OS) runtime sets strict policies at the hardware level for the accelerator. It can only access data and execute code that is part of the application process and if it accesses anything outside of the expected data, the OS runtime gets notified and can shut down the accelerator access by the application without affecting the rest of the system. A memory management unit (MMU) and other hardware to support it are therefore required by the HSA standard.
Shared virtual memory (SVM)
SVM allows the accelerator to access the application’s data directly and process it. That requires an MMU in hardware. HSA accelerators require it for system security reasons already, so no problem here.
Accelerators without SVM using OpenCL 1.x or the common CUDA API require the CPU to do a lot of work including parse application data, select/copy all data to/from the accelerator (which may need a dedicated buffer), and validate results. There is no concept of passing a pointer and allowing the accelerator to operate on shared memory. Often multiple data must be copied to the accelerator, but only one set of data is chosen. This can waste a lot of time to copy if we don’t know in advance which datasets are required. This copy overhead can seriously degrade the performance benefit of the accelerator.
This performance degradation is eradicated on an HSA accelerator. SVM allows the accelerator to parse and only access the application data it needs directly. As an added benefit, the accelerator and the CPU can access the same data in memory, avoiding unwanted duplicates.
Platform atomic operations
Anyone that has programmed with multithreaded code on a CPU knows how useful atomic operations are for ensuring that two threads can operate on the same data safely. Atomic operations are used in many different ways for implementing semaphores, mutexes, histograms, and many other tasks that require a particular order of execution or of access to work correctly. HSA compatible accelerators must support 32-bit or 64-bit atomics, as threads running on the CPU and on the accelerator operate and synchronize with each other very efficiently using atomic operations. Older accelerators without it always require arbitration using software APIs on the CPU. Software arbitration is very inefficient and these systems end up using far more CPU cycles that are better spent on other tasks.
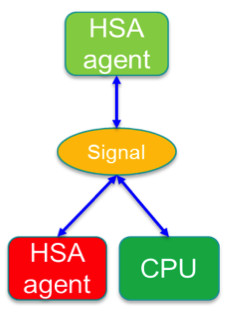
HSA signals and doorbells
This is something special to HSA and a very significant feature for power-efficiency. You can consider these “atomics with benefits.” HSA Signals are data types created by the runtime that behave similar to atomically updated variables in memory. However, they allow the hardware to monitor and notify state changes, e.g. when a value is changed by an application thread or by an accelerator. One or more accelerators can update an HSA signal, listen and wait on a signal state change, and – if they have nothing else to do – go to sleep while waiting and be woken up immediately when something has changed. By using HSA signals, one accelerator can notify other accelerators directly that data is ready and these can start their processing immediately. If implemented fully, the CPU doesn’t need to perform any coordination and can stay asleep. This is a significant power saving feature because the only hardware that is needed for a task is only active when needed. HSA signals can be used easily everywhere in the software architecture and even HSA-based OpenCL implementations benefit.
User queues and dispatch
If you have programmed any accelerator using OpenCL or CUDA and followed in the debugger how it reaches the hardware, you will have noticed layers upon layers of software levels that the accelerator code and data must pass through until it finally reaches the hardware to be processed. HSA removes this inefficiency and cuts out the middle layers by defining a hardware-based user queue dispatch mechanism that can be directly accessed from the application runtime. The architected queuing language (AQL) that a packet processor of an accelerator uses allows any accelerator to either dispatch work to itself, to the CPU of the system to call OS runtime functions, or to other accelerators.
Cache coherency
Most HSA accelerators have caches that keep frequently used data close to the execution units. But since other processors in the system may also access the cached system memory, the application and the hardware must make sure that their content doesn’t get stale – especially in multithreaded execution. HSA accelerators therefore must provide mechanisms to keep the cached data current and either flush out pending data or invalidate cached data if other processors access the cached system memory. Cache coherency can be automatically enforced by hardware bus protocols or alternatively require instruction controls, which in the case of HSA is part of the definition.
With that, I hope I’ve made you interested enough to eagerly wait for the next blog entry, where I will touch on the HSA memory model HSAIL and how HSA integrates into today’s embedded systems.



