
Machine learning and Industrial IoT: Now and into the future
September 20, 2017

Traditional ML algorithms are useful when the amount of data to be processed is relatively small and the complexity of the problem is low. But what about larger problems with a lot more data?
To serve target customers better than their competition, embedded design teams today are looking into new technologies such as machine learning (ML) and deep learning (DL). ML and DL allow these designers to develop and deploy complex machines and equipment faster and with limited resources. With these technologies, design teams can build complex models of a system or systems using a data-driven approach.
Instead of using physics-based models to describe the behavior of the system, ML and DL algorithms infer the model of a system from data. Traditional ML algorithms are useful when the amount of data to be processed is relatively small and the complexity of the problem is low.
But what about larger problems with a lot more data, like the autonomous vehicle? This challenge requires DL techniques. This emerging technology will push us into the next era of control design and Industrial Internet of Things (IIoT) applications.
Current applications of machine learning for industrial assets
First, consider the application of ML technology for condition-based monitoring of industrial assets. ML has helped transition condition-based monitoring applications from an era of reactive and preventive maintenance to one of predictive maintenance. These techniques are being used to detect anomalous behavior, diagnose problems, and, to some extent, predict the remaining useful life of industrial assets such as motors, pumps, and turbines.
The workflow for developing and deploying models based on ML is shown in Figure 1.
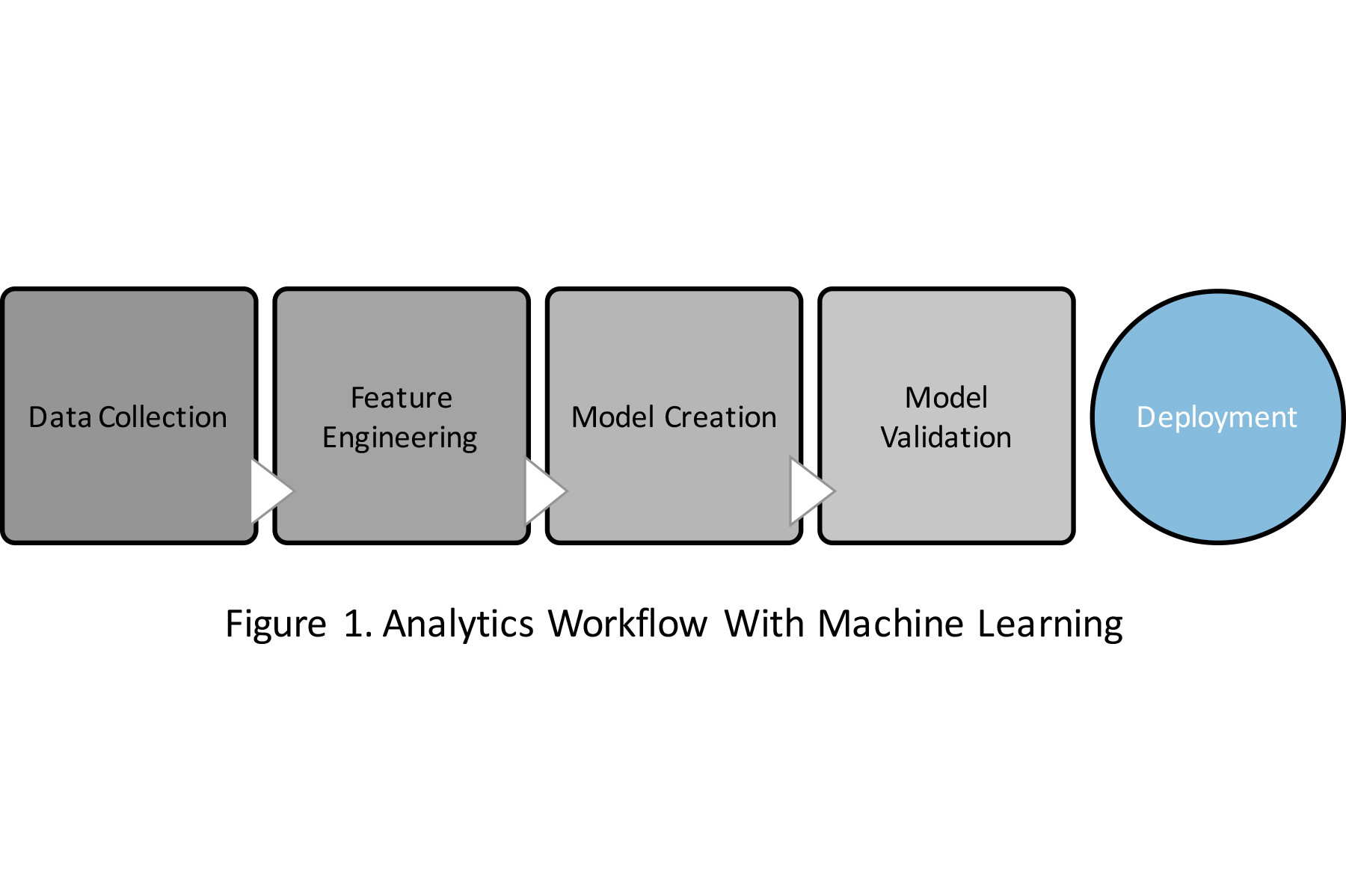
Figure 1. Analytics workflow with machine learning
Look at how this workflow is used to monitor the health of a motor. Data is collected from multiple types of sensors, such as accelerometers, thermocouples, and current transducers attached to the motor. The feature engineering step usually consists of two parts: feature extraction and feature reduction (Figure 2).
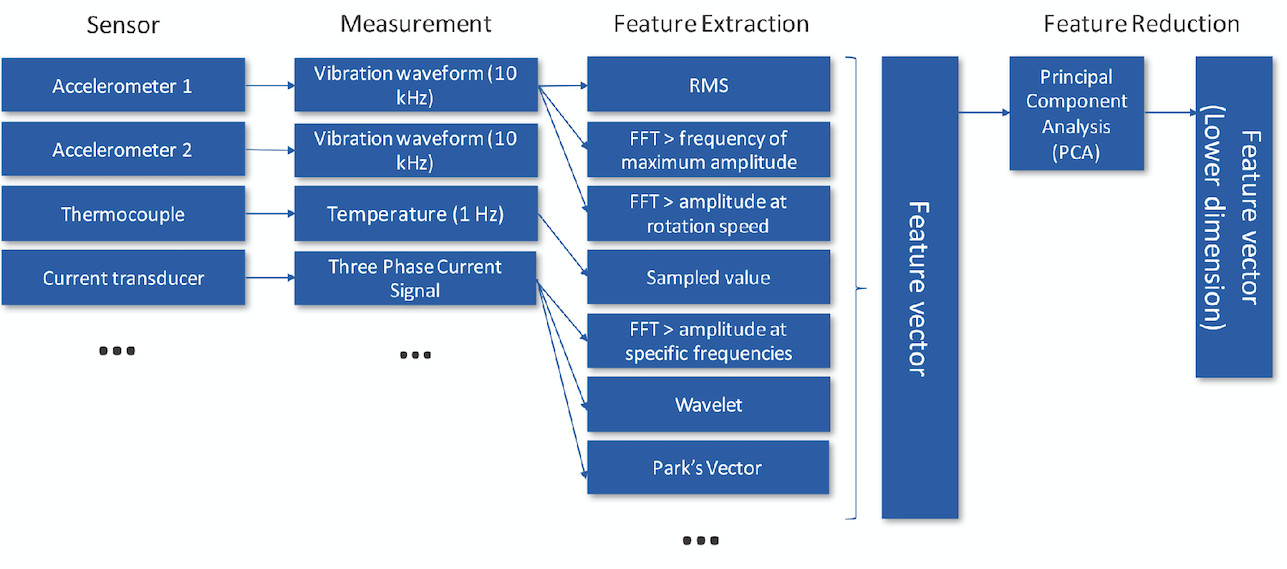
Figure 2. Feature engineering
Feature extraction is used to derive useful information from the raw data (or waveform) to understand the health of the asset. For example, the frequency spectrum of the current signal from the motor has information embedded in it that can be used to detect failures, as shown in Figure 3. The average amplitude across different frequency bands in the spectrum can serve as features that are extracted from the current signal. Features extracted from multiple sensors may have redundant information in them.
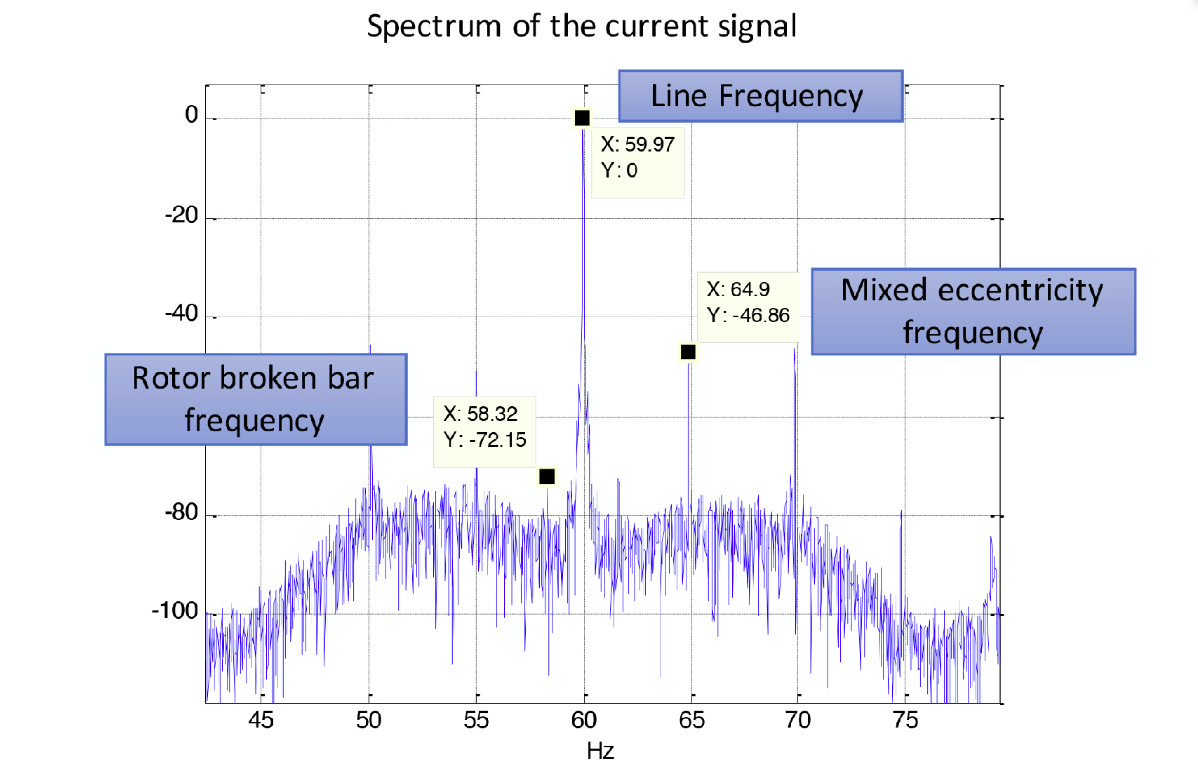
Figure 3. Feature extraction from a motor current signal
A feature reduction method, such as principal component analysis (PCA), can be used to reduce the number of features that are finally used to build a model. Reducing the number of features reduces the complexity of the ML model that is to be used. The reduced set of features is represented as a vector (or array) and input into the ML algorithm used in the model creation step.
Types of machine learning
Model creation and validation is an iterative process through which you experiment with several ML algorithms and pick the one that works best for your application. An unsupervised ML algorithm, such as the Gaussian mixture model (GMM), can be used to model the normal behavior of the motor and detect when the motor starts to deviate from its baseline. Unsupervised methods are good for discovering hidden patterns in the data without the need for labeling the data.
Whereas unsupervised techniques can be used to detect anomalies in the motor, supervised algorithms are required to detect the cause of the anomaly. In supervised methods, the algorithm is presented with pairs of the input data and the desired output. This data is referred to as labeled data. The algorithm learns the function that maps the inputs to the outputs. The data used to train the ML algorithm comprises features extracted under normal and faulty conditions. The features are clearly identified using a label that signifies the state of the motor. Support vector machines (SVM), logistic regression, and artificial neural networks are commonly used supervised ML algorithms.
A challenge with traditional ML techniques is the feature extraction process. It is a brittle process that requires a domain expert’s knowledge, and is usually the point of failure in the ML workflow.
A move towards deep learning workflows
DL algorithms have recently gained popularity because they remove the need for the feature engineering step. Data acquired from the sensors (raw measurements) can be directly input into the DL algorithms, as shown in Figure 4.
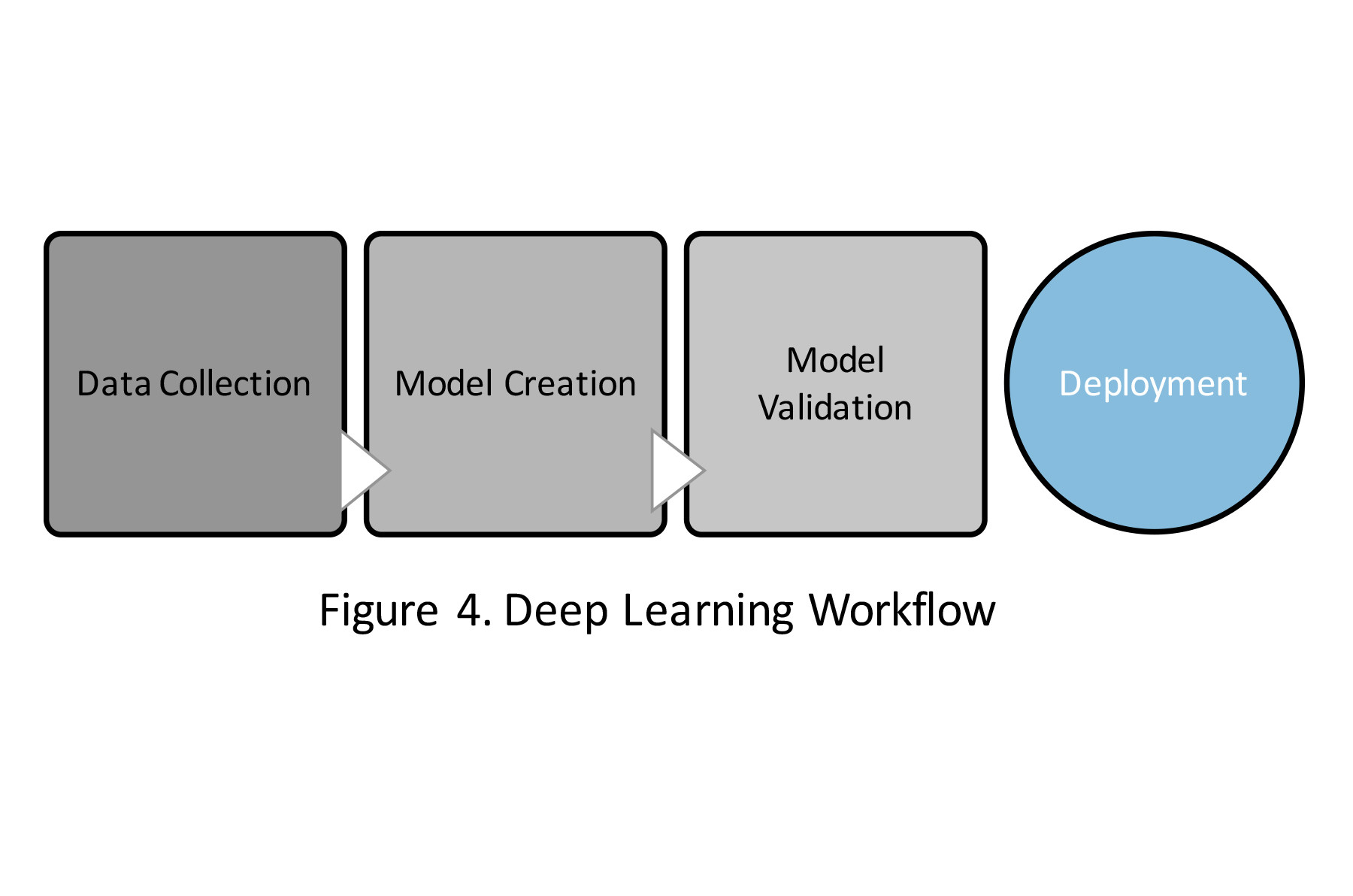
Figure 4. Deep learning workflow
DL algorithms are based on artificial neural networks. Artificial neural network learning algorithms are inspired by the structure and functional aspects of biological neural networks. These algorithms are structured in the form of an interconnected group of computational nodes (artificial neurons) organized in layers. The first layer is referred to as the input layer, which interfaces to the input signal or data. The last layer is the output layer, and the neurons in this layer output the final prediction or decision.
In between the input and the output layer, there are one or more hidden layers (Figure 5). The outputs of one layer are connected to nodes in the next layer by weighted connections. A network learns a mapping between the input and output by modifying these weights. By using multiple hidden layers, DL algorithms learn the features that need to be extracted from the input data without the need to explicitly input the features to the learning algorithm. This is referred to as “feature learning.”
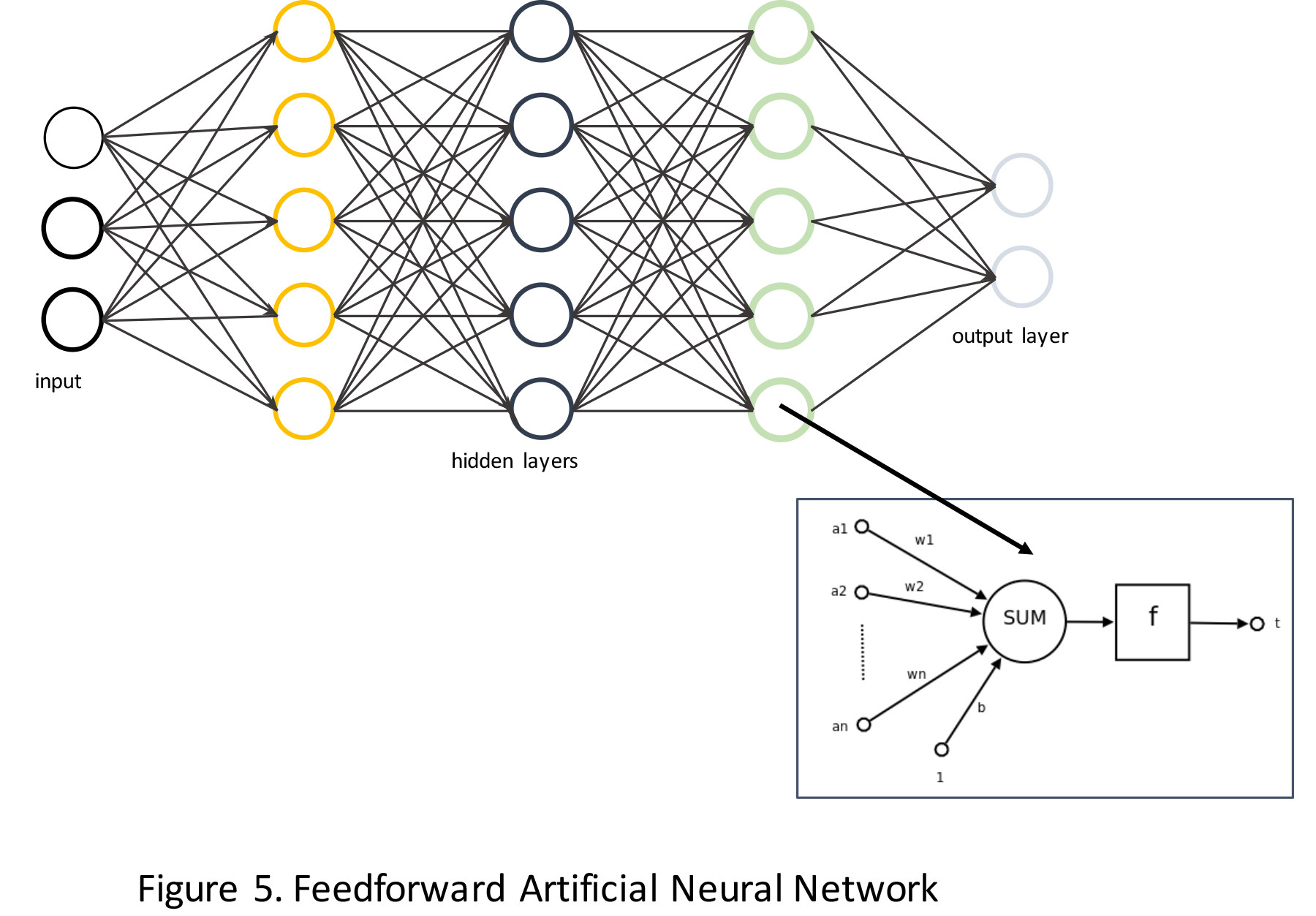
Figure 5. Feed-forward artificial neural network
Designing with deep learning technology
DL has seen recent success in IIoT applications mainly because of the coming of age of technological components, such as more compute power in hardware, large repositories of labeled training data, breakthroughs in learning algorithms and network initialization, and the availability of open source software frameworks.
What follows are some main considerations for designing systems with DL technology.
Topologies
DL is an evolving field and numerous network topologies are currently in use[1]. A few of these networks that show promise for control and monitoring IIoT applications are:
- Deep neural networks (DNNs) are fully connected artificial neural networks with many hidden layers (hence deep). These networks are excellent function approximators and, for example, can be used in the application of power electronics control.
A simulation model of the system you are trying to control can be used to build a controller using deep networks, as well as to generate the training data. With this, you can explore states (boundary/corner conditions) that are usually difficult to control using traditional methods.
- Convolutional neural networks (CNNs) are designed to take advantage of the two-dimensional structure of input signals, such as an input image or a speech signal. A convolutional network is composed of one or more convolutional layers (filtering layers), followed by a fully connected multilayer neural network.
These networks are successful in problems such as defect detection in imaging and object recognition. They are also used for scene understanding in advanced driver assistance systems (ADAS).
- Recurrent neural networks (RNNs) are based on algorithms that make use of sequential (or historical) information to make predictions. These networks are good for time-series analysis. A traditional neural network assumes that all inputs (and outputs) are independent of each other in time or order of arrival. RNNs record state information, which stores information about the past and uses the information calculated so far to make the next prediction.
In IIoT applications, RNNs are good for learning historical behavior and using that to predict events in the future, such as the remaining useful life (RUL) of an asset. The long short-term memory (LSTM) network is good for these kinds of applications[2].
- Deep reinforcement learning (DRL) is good for designing adaptive control systems that operate in complex dynamic environments.
Consider controlling robots deployed in warehouse operations where the robots must dynamically adapt to new tasks. Reinforcement learning–based controllers learn a task by the reward they receive for performing an action that moves them closer to the goal. For example, the controller receives an image from a camera that shows the current position of a robot arm and uses the information in the image to learn how to move the arm closer to the target (Figure 6)[3]. The DL-based controller can be trained using a robot simulator or by observing the real robot in action.

Figure 6. Deep reinforcement learning for robotic control application
Training
DNNs require large amounts of training data that preferably include data from all the different states or conditions that the network needs to learn. For most applications, the available data is predominantly from the normal working condition of the system with a small sampling of data from other states.
Data augmentation is a technique used to improve this imbalance in data, where you can start with the existing small sample set and create additional synthetic versions by transforming the data. You can also use simulation models of the system to create training data.
Another challenge is the difficulty in collecting the large amounts of data required to train these networks. Transfer learning is one approach you can use to mitigate this problem. Using transfer learning, you can start with a pre-trained neural network (most DL software frameworks provide fully trained models that you can download) and fine-tune it with data from your application.
Hardware
Training deep networks has enormous processing requirements. GPUs have emerged as the primary option for training deep networks. GPUs are attractive and almost a necessity for training because of high computation performance, large memory, high memory bandwidth, and a choice of programming tools.
FPGAs, furthermore, are good targets for deploying trained networks. FPGAs provide lower latency, better power efficiency, and determinism, especially for deployment of these networks on embedded devices for control systems that operate in a tight loop with I/O.
Software
A reason for the rapid adoption and success of DL is the availability of mature software frameworks. Some of the common ones are TensorFlow, Caffe, Keras, and Computational Network Toolkit (CNTK)[4, 5, 6, 7]. These frameworks support different operating systems such as Windows and Linux, and languages such as Python and C++. Most of these frameworks have support or examples for implementing the latest DL networks. They also support learning on GPUs.
Deep learning: A new direction in IIoT control design
DL is an exciting new direction in artificial intelligence and a promising technology to solve next-generation problems in industrial control design applications.
A quick way to get started with DL is by downloading one of the open source frameworks mentioned previously and experimenting with the tutorial examples. Start with an example that is similar to your application and use transfer learning to get operational quickly.
Dinesh Nair is chief architect at National Instruments.
National Instruments
LinkedIn: www.linkedin.com/company/3433
YouTube: www.youtube.com/user/nationalinstruments
References:
1. Veen, Fjodor Van. "The Neural Network Zoo." The Asimov Institute. October 28, 2016. Accessed September 20, 2017. http://www.asimovinstitute.org/neural-network-zoo/.
2. "Long short-term memory." Wikipedia. August 27, 2017. Accessed September 20, 2017. https://en.wikipedia.org/wiki/Long_short-term_memory.
3. Zhang, Fangyi, Jürgen Leitner, Michael Milford, Ben Upcroft, and Peter Corke. "Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control." [1511.03791] Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control. November 13, 2015. Accessed September 20, 2017. https://arxiv.org/pdf/1511.03791.pdf.
4. "TensorFlow." TensorFlow. Accessed September 20, 2017. https://www.tensorflow.org/.
5. "Caffe." Caffe | Deep Learning Framework. Accessed September 20, 2017. http://caffe.berkeleyvision.org/.
6. "Keras: The Python Deep Learning library." Keras Documentation. Accessed September 20, 2017. https://keras.io/.
7. "Video: Unlock deeper learning with the new Microsoft Cognitive Toolkit." Microsoft Cognitive Toolkit. Accessed September 20, 2017. https://www.microsoft.com/en-us/cognitive-toolkit/.



