
2018 embedded processor report: Rise of the neural network accelerator
February 05, 2018
Blog

Different embedded processing solutions are used to execute neural network algorithms depending on the application, leaving a range of options for AI and ML developers to choose from.
AI and machine learning (ML) applications represent the next big market opportunity for embedded processors. However, conventional processing solutions were not designed to compute the neural network workloads that power many of these applications, necessitating new architectures that can meet the growing demand for intelligence at the edge.
With billions of connected sensor nodes being deployed across the IoT, one thing has become clear: Automation is needed everywhere. Given the nature of IoT systems, many of which have serious economic, productivity, and safety implications, this need transcends the use of simple rules engines or programming thresholds. In response, industry has turned to AI and ML.
Many of today’s AI and ML applications rely on artificial neural networks, which are algorithms that analyze different aspects of a data set by organizing its defining characteristics into a series of structural layers. These networks are initially modeled on high-performance compute platforms that teach the algorithm to make decisions or predictions depending on certain parameters. Afterwards the algorithm can be optimized and ported to an embedded target, where it makes inferences based on input data received in the field.
Different embedded processing solutions are used to execute neural network algorithms depending on the application, leaving a range of options for AI and ML developers to choose from. But, as Mike Demler, Senior Analyst for The Linley Group and Co-Author of the firm’s “Guide to Processors for Deep Learning” asserts, each of these comes with tradeoffs in terms of power, performance, and cost.
“There’s no one type of embedded ‘AI processor,’” Demler says. “Neural network engines might use CPUs, DSPs, GPUs, or specialized deep learning accelerators, or a combination.
“The trend is definitely toward adding an accelerator to the mix along with CPUs, GPUs, and DSPs. The reason is that they are more area- and power-efficient than the other general-purpose cores,” he continues. “As the use of standard, open deep learning frameworks like Caffe and TensorFlow increases, along with readily available open source networks like GoogleNet and ResNet, it’s easier for IP vendors to design cores that have hardware specifically dedicated to run the various neural network layers. That’s why a lot of accelerators keep adding larger and larger multiplier-accumulator arrays, because most of the calculations in a neural network are MACs.”
Emerging architectures for AI workloads
A major focus for IP vendors targeting neural network workloads is flexibility, as requirements are changing rapidly in the evolving AI market. An example of this can be found in CEVA’s recently released NeuPro AI processor architecture, which consists of a fully programmable vector processing unit (VPU) alongside specialized engines for matrix multiplication and computing activation, pooling, convolutional, and fully connected neural network layers (Figure 1).
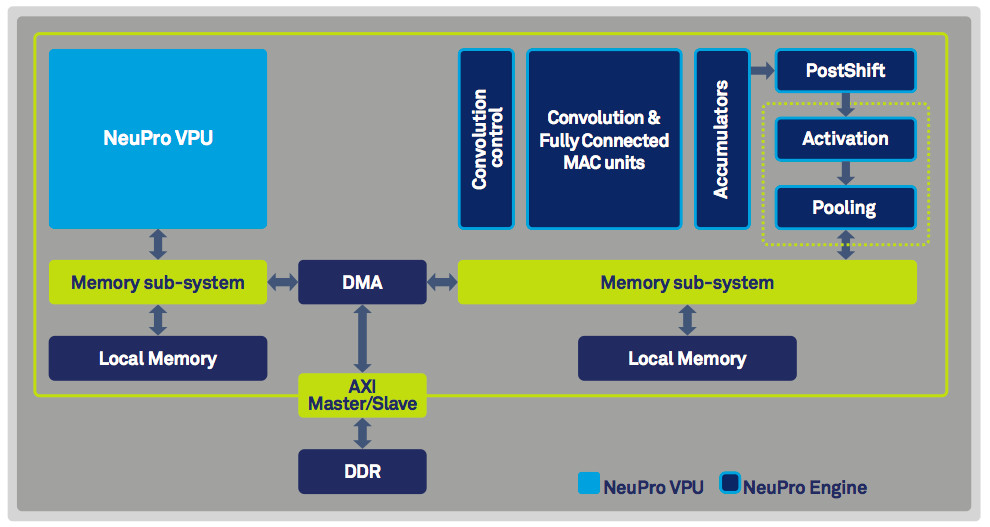
One common challenge in processing neural network workloads is the need to transfer large data sets to and from memory. To overcome this, the NeuPro architecture incorporates direct memory access (DMA) controllers that enhance DDR bandwidth utilization.
One of the architecture’s more intriguing features is the ability to dynamically scale resolution to accommodate the precision requirements of individual network layers. According to Liran Bar, Director of Product Marketing for Imaging and Computer Vision at CEVA, this helps maximize the accuracy of neural network inferencing.
“Not all layers require the same level of precision. In fact, many commercial neural networks require 16-bit resolutions in order to keep high accuracy, but at the same time 8-bit is sufficient for some layers,” Bar says. “NeuPro determines the precision of each 8- or 16-bit layer in advance to enable full flexibility. For example, when using the NP4000 product, this allows 4000 8x8, 2048 16x8, or 1024 16x16 MACs to be dynamically selected at run time.”
A similar feature is available in Imagination Technologies’ PowerVR Series2NX, a neural network accelerator (NNA) with native support for bit depths down to 4 bits. The PowerVR Series2NX takes dynamic scaling to the extreme, however, supporting 4-, 5-, 6-, 7-, 8-, 10-, 12-, and 16-bit resolutions on the same core for even greater precision (Figure 2).
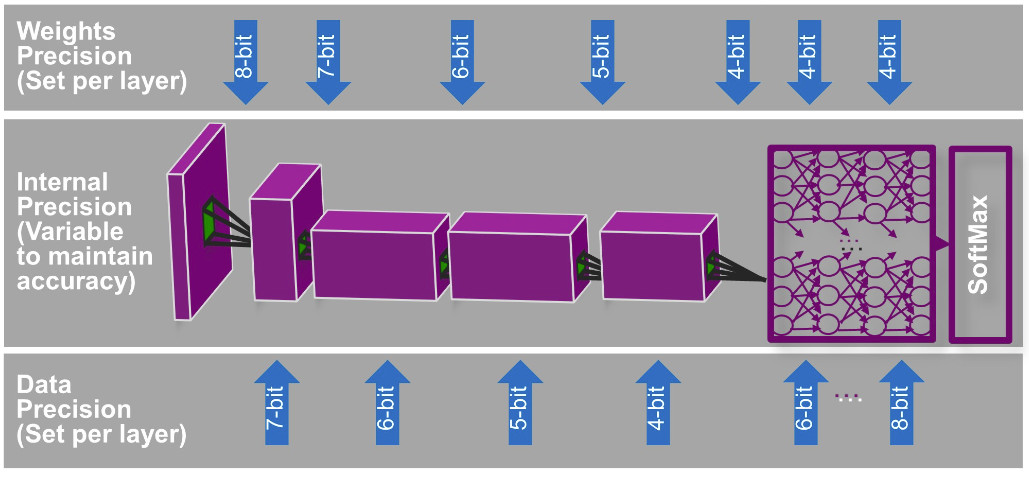
“One can see the NNA architecture as a tensor processing pipeline,” says Russell James, Vice President of Vision and AI at Imagination Technologies. “It has a neural network compute engine optimized for fast convolutions over large tensors (input data and weights), complemented by various other units performing element and tensor operations such as activations, pooling, and normalization. The architecture also employs an optimized dataflow that enables operations to be grouped into passes, and thus minimizes external memory access.”
Another unique capability of the PowerVR Series2NX is its ability to convert data into an exchange format in memory that can be read by CPUs or GPUs, which gives heterogeneous systems a head start in neural network processing. Imagination offers a Network Developer Kit (NDK) for evaluating the core that contains tools for mapping neural networks to the NNA, tuning network models, and converting networks developed in frameworks such as Caffe and TensorFlow.
Neural network processing: Everyone’s in
Outside of IP vendors, major chipmakers also continue to position themselves to take advantage of AI workloads. NVIDIA Tegra and Xavier SoCs combine CPU, GPU, and custom deep learning accelerators for autonomous driving systems, while Qualcomm continues to build ML features into its Hexagon DSP. Intel, for its part, has had an 18-month-long shopping spree acquiring the likes of Mobileye, Movidius, and Nervana who develop neural network technologies for various markets. Even Google has created a tensor processing unit (TPU).
Each of these companies is taking a different approach to processing neural network workloads, and each architecture addresses slightly different use cases. But when it comes to AI for developers, the more options, the better.



