
Big data for engineers and scientists, part 3: IT, enterprise applications, and big data
April 17, 2017

Read "Big data for engineers and scientists, part 2: Analyzing, processing, and creating models" here. Many organizations have realized the value in d...
Many organizations have realized the value in data that is collected from their products, services, and operations. They have created new executive positions, such as Chief Information Officer (CIO), whose main focus is on the proper use and protection of this new big data resource. The CIO subsequently enlists the information technology (IT) team to implement new policies and processes for data which includes:
- Governance: Ensure the integrity of the data by controlling the storage, access, and processing of data.
- Access: Make data available to engineering, operations, warranty, quality, marketing, and sales groups.
- Processing: If the data is large enough, a specialized processing platform becomes a necessity to eliminate delays in transferring data and decreasing the time to process data.
To comply with these new requirements, the IT organization is taking to new technologies and platforms for storing and managing these vast and ever-increasing sets of data. Because of this, you need to work more closely with IT teams in order to gain access and setup a workflow that enables you to process your data. In this new environment, using a software analysis and modeling tool that works with the systems that your IT teams are using to store, manage, and process big data, as well as one that you are familiar with, enables you to effectively use this data in everyday activities.
Big data platforms and applications
There are a number of platforms that IT organizations are adopting for the storage and management of big data. These platforms provide not only the infrastructure for storing big data, they also support a wide variety of applications that are used to process big data in different ways. These applications can be roughly categorized into two categories: batch processing of large, historical sets of data, and real-time or near real-time processing of data that is continuously collected from devices. This second case is often referred to as streaming and is found in most Internet of Things (IoT) applications.
Hadoop
Hadoop is designed around distributed storage and distributed computing principles. It is comprised of two major subsystems that coexist on a cluster of servers, allowing it to support large data sets.
- HDFS: The Hadoop Distributed File System (HDFS) provides a large and fault-tolerant system for storing data.
- YARN: Yet Another Resource Negotiator (YARN) manages the highly scalable applications that run the Hadoop cluster and process data stored in HDFS.

[Figure 1 | The main building blocks of Hadoop and some common applications that run on it. Copyright: © 1984–2017 The MathWorks, Inc.]
Batch applications and creating models
Batch applications are commonly used to analyze and process historical data that has been collected over long periods of time or across many different devices or systems. Having the ability to use these batch processing applications enables you to look for trends in your data and develop predictive models that were not possible in the past with large sets of data.
Two of the more popular batch processing applications that operate on Hadoop include:
- Spark:A more generalized framework that optimizes in-memory operations, making it highly desirable for machine learning applications.
- MapReduce: A highly structured framework consisting of map and reduce functions, making it useful for large data analysis and data transformation applications.
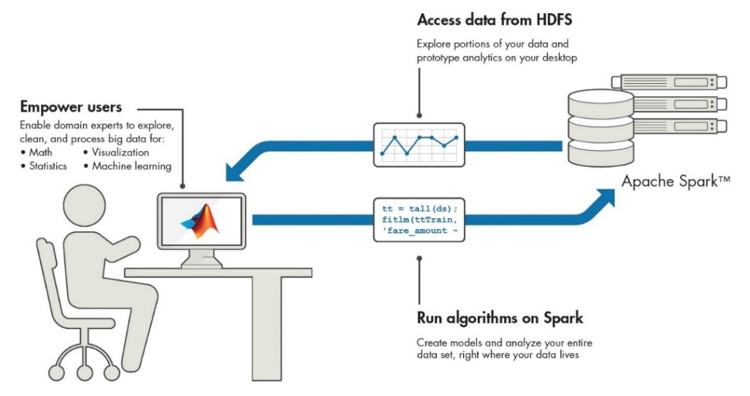
[Figure 2 | Using MATLAB with Hadoop and Spark. Copyright: © 1984–2017 The MathWorks, Inc.]
Streaming applications and model integration
Using models developed from sets of historical data, along with a streaming application such as Kafka or Paho can add more intelligence and adaptive capabilities to your products and services. Examples of these differentiated capabilities include: predictive maintenance, which greatly reduces unnecessary maintenance as well as unplanned downtime; services that tune heavy equipment such as ships, locomotives, and commercial vehicles to better perform within its operating environment for better fuel economy and enhanced operation; and building automation systems that operate a building’s systems at the lowest cost possible, while still maintaining a comfortable environment.
Engineers at Mondi Gronau created a Statistical Process Control (SPC) application that incorporates predictive models developed using MATLAB. This system not only allows their machine operators to monitor the operation of their many complex manufacturing lines, but also provides alerts that indicate when a machine is trending towards a failed condition. These alerts allow the operator to make adjustments before any manufacturing tolerances are exceeded, thereby reducing the loss of raw material.
In many cases, these kinds of services are usually developed in conjunction with enterprise application developers and system architects. But the challenge is how to integrate your models into these systems in an effective way. Porting models to another language is time consuming and error prone, requiring extensive work each time an update is made to a model. Developing predictive models in typical IT languages is difficult. Engineers and scientists who have the domain expertise required for developing these models are not familiar with these languages, and these languages don’t always include the functionality needed to adequately process and create models from engineering and scientific data.
Enterprise application developers should look for a data analysis and modeling tool that are not only familiar to their engineers and scientists, but that also provides the domain specific tools they need. These tools must also scale for use in developing models and large datasets using Hadoop-based systems that provide capabilities such as a highly robust application server and code generation, enabling a direct path for deploying models into enterprise applications.

[Figure 3 | Integrating models with MATLAB. Copyright: © 1984–2017 The MathWorks, Inc.]
Other applications for data access
There are many other applications that allow access to big data that are being adopted. Some of these include interfaces which allow access to the data stored in HDFS using database-type semantics. Hive and Impala are two such applications that allow data to be accessed and processed using the Structured Query Language (SQL). This is a well-established and widely used language for working with data in relational databases.
NoSQL databases, which have been architected to support different big data use cases, are also being adopted. Many times these databases support a subset of the SQL language for accessing and processing data, but may also have additional interface capabilities that traditional databases don’t offer.
Scientists, engineers, and IT
As discussed above, various systems are used to store, manage, and process big data. By working closely with your IT team and utilizing a tool such as MATLAB, you can create a workflow that is familiar, enabling you to easily and efficiently work while gaining insight from a vast collection of data.
IT managers and solution architects can use modeling tools such as MATLAB to enable the scientists and engineers in their organizations to develop algorithms and models for smarter and differentiated products and services. Simultaneously, you are also enabling your organization to rapidly incorporate these algorithms and models into your products and services by leveraging production-ready application servers and code generation capabilities that are found in these tools.
The combination of a knowledgeable domain expert who has been enabled to be an effective data scientist, along with an IT team capable of rapidly incorporating their work into the services and operations of their organization makes for a significant competitive advantage when offering the products and services that customers are demanding.




