
Emulation for Automotive Functional Safety
August 27, 2018
Product

As designers, we all want our designs to work correctly. We have pride of ownership. So we verify like crazy to make sure we did a good job.
This is part six of a series. Read part five here.
As designers, we all want our designs to work correctly. We have pride of ownership. So, we verify like crazy to make sure we did a good job. But verification takes time, and projects have deadlines or else they don’t make money. So, we do the best job we can, helped with good verification tools, and, by and large, we do OK.
But the consequences of failure are not equal for all designs. If your laptop or your game console doesn’t work, it may be frustrating, and it might even cost you some money, but no lives are threatened. If, on the other hand, system failure will put people or significant property at risk, then we’ve entered the realm of functional safety.
This used to be the sole domain of low-volume, high-cost projects for the military or for civilian aircraft. All those electronics in the airplane in which you made your last trip? They must work; failure is not an option. Your life depends on it.
But times are changing: it’s no longer just tanks and missiles and planes for which safety is paramount. There are all the electronics being designed into automobiles, both driven and driverless. That brings functional safety down from the rarified world of military/aerospace and directly into the hustle and bustle of cars built for consumers. Volumes of safety-critical chips should skyrocket.
Failure modes
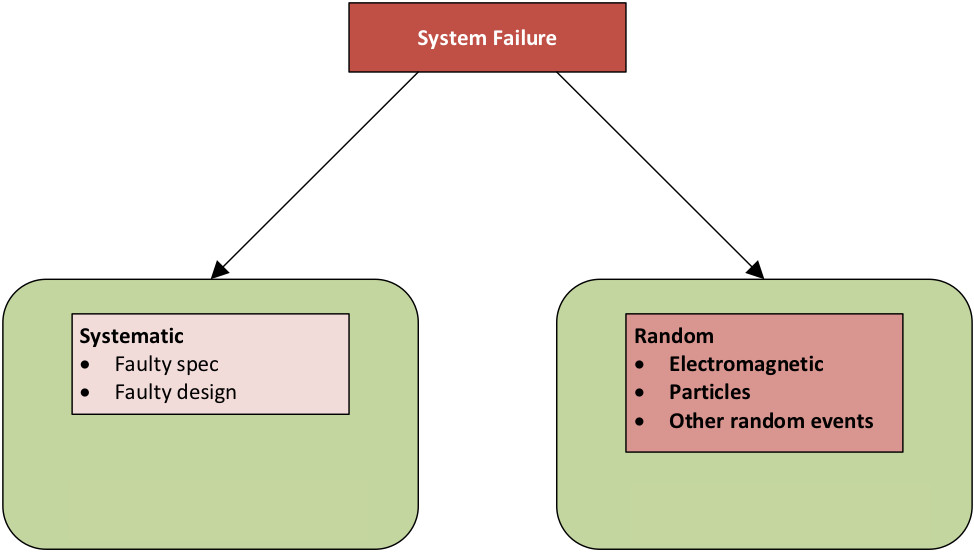
Broadly speaking, there are two classes of failure:
- Systematic failures: these are problems arising from mistakes either in the original design spec or in the implementation of the spec. This is where traditional verification is the solution.
- Random failures: These are any other kind of failure caused by uncontrollable forces. This includes electromagnetic influence, so-called “single-event upsets” like alpha particles, and any other such effect. These events can change the state of at least one flip-flop – any flip-flop – and, as circuit sizes shrink, it even becomes possible for a single event to affect multiple flip-flops because they’re so close together.
The random failure domain is the one that’s harder to account for in a design. There are techniques that have been used for low-volume systems for years – things like triple-module redundancy. But they’re too expensive for consumer-oriented automobiles.
So, the goal changes from making sure nothing can ever go wrong (practically speaking) to arranging for any system experiencing a fault to naturally move into a safe state. That doesn’t mean that the system keeps working as if nothing happened, but it does mean that the system won’t get into some unpredictable state that could be a danger to those around or within it.
As a designer, your task then becomes to minimize the number of possible faults, and then protect against those that remain. Undetected faults – ones that are not propagating to the system and so have no discernable effect on any output or result in no illegal internal states – aren’t a problem, and don’t need protective design. Detectable faults, on the other hand, that do propagate to the system rely on extra circuits for protection. At present, such circuits are manually designed once you know where the critical faults lie.
Identifying and Protecting Against Faults
So how do you find these faults? That’s a job for… we’ll use the word “simulation” in the broad sense, although, as we’ll see, EDA simulators aren’t up to the task. The idea is to simulate the system while injecting faults to understand which ones result in an undesired state. And there are a lot of possible faults – in theory, multiple faults per flip-flop. And ISO 26262 recommends fault injection at the gate- level, making the potential fault campaign to verify the system an even larger task compared to an RTL-based design.
There are several challenges here that make the task even harder than it might already seem. First, there are several kinds of faults to test for. The most frequently used models are stuck-at faults, transient faults, and bridging faults. And such faults are typically injected and tested one at a time, since this reduces the complexity of testing.
In addition, the list of faults needed to complete a fault campaign on a design can be extremely large. For instance, a list of 100,000 faults might be needed for testing a microprocessor alone, so full-SoC fault campaigns will stretch the limits of some techniques, such as simulation.
So-called fault pruning could help reduce the length of the fault list, and it’s an area of active research in which Mentor is heavily involved. But, truth be told, even after pruning, you’ll still have a long list.
This makes for an enormous project – if you’re using a traditional EDA simulator to do the job. The 100,000-gate processor alone could take on the order of 11 days, putting a full SoC out of reach. That makes this a job for emulation, and Mentor provides a Fault App for the Veloce emulator family.
You start by providing a list of the faults that must be injected, and Veloce Fault App systematically works through the list, logging all the results. It still takes time, but, on any given run, as soon as an unexpected state is detected, that particular run stops and is recorded (in other words, the slowest faults are the unobservable ones that don’t end early).
You don’t have to list absolutely every net in the device, since there may well be areas that clearly aren’t going to be of concern. But everything else should be represented
Once complete, you have a list of faulty outputs, undetected faults, and the overall fault coverage for the design – all useful in allowing you to harden your device for functional safety requirements.
There’s no question that providing for functional safety takes additional work. But it’s much less work than a re-design after recall of a component or vehicle – and a lot less expensive! And Veloce emulators, armed with the Veloce Fault App, can take care of the tedious parts of the task, leaving the more interesting protective designs for your design skills.
Richard Pugh, Product Marketing Manager, Mentor, a Siemens Business
Richard Pugh has 30 years of experience in electronic design automation, working in IP, ASIC, and SoC verification with positions in application engineering, product marketing, and business development at ViewLogic, Synopsys, and Mentor. He is currently the product marketing manager for Mentor’s emulation division. Richard holds an MSc in Computer Science and Electronics from University College London and an MBA from Macquarie Graduate School of Management, Sydney.
Mentor, A Siemens Business



