
Leveraging static code analysis for medical device software
December 01, 2010

When used correctly, static analysis has proven to be highly effective in improving software quality for safety-critical code.
Medical devices are using more software code than ever before. However, while software provides medical devices with significantly more capability and flexibility, it also brings additional complexity, which translates into increased risk of failure. About 20 percent of medical device recalls today are caused by software defects, and the number is rising.
The Federal Drug Administration (FDA) oversees the quality of medical devices sold in the United States, and companies wishing to release a medical device must receive FDA 510(k) clearance. While post-market failures are investigated, the FDA is putting stronger focus on prevention and recommending that static code analysis be used as part of the approach.
The value of sophisticated defect detection
Modern static code analysis tools use sophisticated techniques to analyze source code to detect potential software defects. Tools try to analyze all logical paths in the code, providing significantly more path and code coverage than traditional forms of testing. Static analysis tools do not require any test cases and can operate even on fragments of code, finding potential program crashes, buffer overruns, memory leaks, data corruption, and more. Static analysis usually operates quickly and can report a range of potential bugs in a relatively short amount of time (see Figure 1).
|
|

For a variety of reasons, static analysis tools do produce some erroneous results, generally called false positives and false negatives. A false positive occurs when the static analysis tool believes there is an error when there isn’t. A false negative is when an error should have been reported but isn’t.
Most modern static analysis tools must perform a delicate trade-off between finding as many good results as possible within an acceptable accuracy level and an acceptable running time. Stated another way, noisy tools that find every problem in a sea of false positives may be of limited value, as are highly accurate tools that find only a small class of issues (see Figure 2).
|
|

Modern static analysis tools have improved analysis techniques to generate useful results at an adequate level of accuracy. Most organizations recognize that static analysis tools, while imperfect, provide significant value in most any software development process.
Making the most of static analysis tools
Modern static analysis tools are relatively new to most medical device manufacturers. For many organizations that are instituting static analysis in their process for the first time, knowledge of best practices can help get the most out of tools in the shortest amount of time and with the least amount of rework.
Tuning
Static analysis tools are delivered with generic settings applying to all types of code bases, and while they find good bugs right out of the box, results can be improved greatly just by tuning the tools for the code (see Figure 3). This helps find more relevant bugs and reduces the search through false positives, which wastes time and causes developer fatigue.
|
|

Many static analysis tools have their own source code parsers that might not understand or have access to all of the code. Configuring the system to analyze all of the code or tuning the system to recognize interfaces inaccessible at analysis time – such as separately verified third-party libraries – ensures the results are optimum and repeatable. Achieving 100 percent code coverage is important to close holes that can increase risk.
Tuning helps uncover real problems. For instance, telling the static analysis tool how a memory allocation mechanism works or when a program exits so that the tool isn’t continuing to track issues along a certain path can help uncover new problems and prune away false ones. This can be a tedious process requiring specific expertise, but it pays off in the long run.
Tuning is typically an ongoing process and should be reviewed periodically to ensure that configurations are used consistently and keep pace with the changes to the code and the environment. Without ongoing tuning, developers will likely miss some important bugs and the team will waste time scrutinizing false positives.
Configuring checkers
Many static analysis tools come with hundreds of checks that cover a range of issues, from concurrency to security to C and C++ pitfalls. Many do not necessarily apply for a given application. For instance, why turn on a C++ specific check when analyzing C code? Determining the right set of checkers requires some trial and error as well as expertise to understand what is going to give the best bang for the buck. Some areas for consideration are: what categories of checkers can result in real problems, which checkers tend to be noisy, and which checkers can be configured to be useful. Once a good set is finalized, lock it down so it is documented and runs consistently.
In a real-world example illustrating the value of checkers, a customer wanted to ensure that their static analysis system was running consistently and requested to be alerted immediately if there was a discrepancy in the system. Developers created a test suite that included test cases for each checker. Whenever they changed the system, they ran the test suite to ensure that every checker was indeed operating as expected. If the results failed, they knew they had a configuration problem that needed to be addressed. If the tests passed, developers dropped the results into their design history file as proof that the system was working as they had documented. This test suite not only gave the customer accountability and assurance, but also decreased their maintenance and administration costs.
Process
Once full coverage is achieved, the system is tuned, and the breadth of analysis is defined, developers can begin using static analysis much more effectively. For medical devices, a typical goal is to examine every single issue reported. Each issue can be categorized in a number of different ways:
- An issue that must be fixed. It will have an appropriate priority assigned that describes its importance and how it must be addressed during the software development process.
- An issue that is correctly flagged, but not likely to manifest as a real-world bug, usually because there is an incorrect environment assumption made by the tool. These types of categorizations signal a potential tuning opportunity.
- An issue that is incorrectly flagged as an error, either a false positive or an outright bug in the analysis tool. These issues also signal a tuning opportunity.
Each of these cases must be carefully reviewed. False positives in particular should be examined for correctness. Liberal documentation is required for each issue, and a robust data retention policy is necessary for full accountability. These triaged defect reports will likely be revisited either in an audit process or in a retrospective if a major bug is found later in the process. It’s common for organizations to go back to the static analysis defect to see how a major bug got through the process. It could signal a broken process or an opportunity to tune the analysis to find better bugs.
Usage model
Static analysis is typically run either in a developer sandbox build and/or through a central build (see Figure 4). At a minimum, analyzing and evaluating the results makes sense to do just before release. However, software development organizations shouldn’t wait to the last minute to address a potentially large pile of bugs, particularly when those bugs could have been addressed earlier as part of a disciplined process. Otherwise, teams risk missing a deadline and changing the code at the worst possible time.
|
|
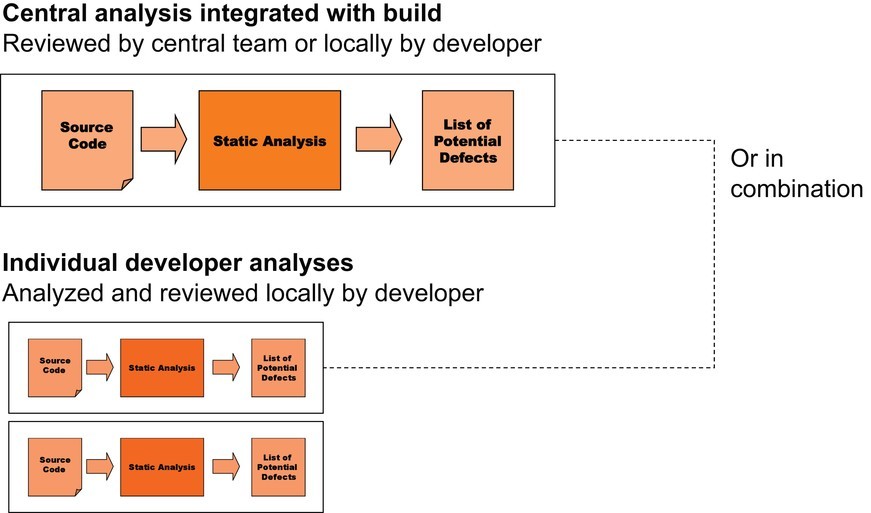
Organizations often automate static analysis as part of a nightly build or a continuous integration build. In this way, results can be reviewed frequently and addressed as they arise. Others perform the bug-finding process earlier by enabling developers to analyze the code they are working on right in their sandbox environment. Developers can get immediate feedback on the quality of their code changes and then fix and verify defects before check-in. The quicker the cycle time, the cleaner the code will be in the repository.
Regardless of where it runs, the technical environment needs to be consistent to ensure that the results are the same. Central and developer builds need to be consistent. A slight change to the analysis settings can result in many more results being reported, and organizations don’t need the added burden of having to review more problems that might be mostly false positives. Creating a highly automated system for developers to use will help ensure consistency.
Many medical device companies check not only the source code into their repositories, but also their actual environment. In this way, traceability is available. Static analysis executables and all the associated configurations, states, and other relevant items should also be checked in regularly to ensure consistency and accountability.
Dealing with backlog
Most organizations begin using static analysis after a significant amount of code has already been developed. Generally, the more code there is, the more bugs will get reported. Thus in rolling out static analysis, management must allocate upfront time to deal with the initial backlog of bugs.
It’s better to try to institute static analysis as early as possible in the development cycle to minimize the backlog, then create a process to deal with the backlog separately from the daily flow of incoming bugs due to day-to-day code changes. Reviewing defects takes time and should be allocated properly among the developers or farmed out to a separate team to pick the defects needing work.
Culture
All development teams are heterogeneous in technical skill levels and in how each individual within the team defines quality. During training and mentoring sessions, the most common arguments are:
- “Yes, this is definitely a bug, but the code has been working so we don’t want to change it.”
- “We should not allow code like this to be in our product.”
- “This scenario would never happen in real life.”
- “This will become a bug if we port the product to another platform in the future.”
- “If you spent just a few more minutes on this, you’ll see it’s clearly a bug.”
Static analysis will deliver bugs of all stripes, from critical must-fix problems to warnings. Some organizations want to be opportunistic and only change the code for provable bugs. Others proactively clean up code and improve quality, even going so far as to “fix” warnings. Teams should have consistency in how they address static analysis results. Review of the results, training/mentoring, and frequent communication are keys to success.
When used correctly, static analysis has proven itself to be highly effective in improving software quality for safety-critical code. Although not strictly required for approval, the FDA recognizes its efficacy. With the proper planning, expertise, and realistic investment, static analysis should yield a significant return on investment and help deliver safe code to the marketplace.
|
|

Code Integrity Solutions
www.codeintegritysolutions.com




