
The quest for measuring multicore performance
June 01, 2012

As multicore processors continue to propagate into various markets and applications, so does the need for standard benchmarks that effectively compare...
While the availability of multicore processors in the embedded marketplace is nothing new, today’s software engineers can find a variety of homogeneous devices as well as complex, heterogeneous Systems-on-Chips (SoCs) as options for their designs. This high level of multicore integration offers many benefits, including smaller, lower-cost, lower-power, and higher-performing end products.
Advancements have been made in the areas of tools and frameworks, and some products have added programming paradigms to help mitigate the development challenge around this complexity. However, the value that highly integrated multicore SoCs provide is discounted if software architects cannot maximize the processing power of every compute element within the multicore processor device.
Software engineers seek full multicore entitlement through a standard method for determining that capability on a particular multicore device. While the market has standard benchmarks for comparing the performance of simple, typically single-core processors, it does not yet have these standard benchmarks or methodologies for comparing the multicore performance (or multicore entitlement) for complex SoCs, making it difficult for software architects to select the best processor for their designs.
The benchmarking challenge
Benchmarking CPU performance was relatively easy in the days when processors were simple and computational performance was the sole focus. As processor architectures evolved, so did the benchmarking challenge. According to Merriam-Webster, one of the definitions of benchmark is “something that serves as a standard by which others may be measured or judged.” In other words, benchmarking is not an absolute, but a relative activity. And therein lies the fundamental challenge when processor architectures differ substantially in their strengths and weaknesses: knowing how to normalize these differences to develop a measure that is both fair and accurate. In practice, the problem is rarely addressed, and end users are left with measures that are difficult to compare in a straightforward manner.
Traditional benchmarks have served the embedded processor market well so far, albeit in limited fashion. These benchmarks are simple to understand and limited in scope, measuring the integer or floating-point computational prowess of a CPU without looking at overall system complexity. At times, the software kernels executed as the test vehicles for such benchmarks are single functions that can be optimized easily by using intrinsic instructions or other specialized features, which can make the gains difficult to translate in true customer applications. As a result, traditional benchmark values provide a first-pass metric to embedded processing engineers when selecting devices and carry weight with prospective vendors.
However, today’s advanced SoCs require more comprehensive benchmarks to reveal true performance and capabilities in addition to any hidden bottlenecks. With so many functions integrated on a single chip, it is becoming increasingly difficult to model and measure real-life use cases. As a result, the industry is already moving toward benchmarks that target specific application areas such as Java acceleration, Android performance, or Web browsing performance. This approach, which differs from synthetic benchmarks, works well for processors with well-defined application segments and gives users a fairly accurate assessment of expected performance.
Multicore complexities
The problem is not so simple for the new generation of embedded multicore processors being deployed in a diverse range of applications, such as medical imaging, industrial automation, mission-critical systems, communications infrastructure, and high-performance computing. Architectural complexity combined with complicated software implementation compounds the problem. The internal connectivity of all of the processing elements and system buses within the SoC architecture affects the computing performance of the device and makes it more difficult to measure and evaluate.
With multicore implementations, several threads can execute in parallel on different cores rather than just multitasking on a single core. This increase in the number of parallel paths and scheduling possibilities makes it even harder to model application behavior and measure performance.
In addition, multicore systems introduce another dimension to the mix: scalability, or how well the architecture scales as more and more cores are employed. Scalability is important not only in choosing the appropriate architecture for the current application, but also in planning for future growth or portfolio expansion. It is a well-known industry fact that application speedup does not increase linearly in proportion to the number of cores, as performance rolls off at some point and in some cases actually diminishes as the number of cores increases. This is largely due to access bottlenecks encountered by the increased number of cores, as well as additional synchronization needs. The speedup also depends on how software is partitioned and how well it can leverage increased parallelism.
But assuming ideal software implementation, there is still much to be said about multicore device architecture (see Figure 1). High-performance devices have incorporated a number of innovations to move data efficiently through a system, thus keeping the cores busy without wasting time in access stalls. High-bandwidth chip-level interconnects and dedicated accelerators create islands of processing engines that work with minimal core intervention and without contributing to memory bottlenecks. Similarly, chained hardware queues with built-in Direct Memory Access (DMA) act as mini assembly lines, relieving the core of interruptions and scheduling these processing tasks.
|
|
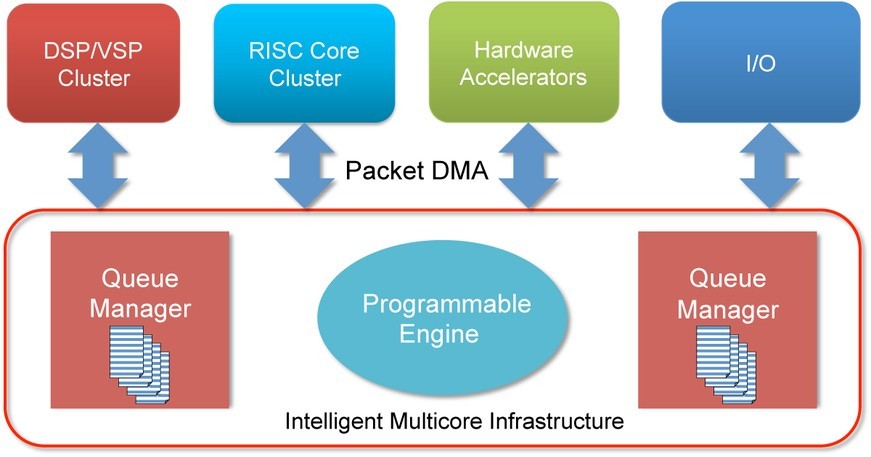
Building blocks for better benchmarks
With chip vendors employing vastly different approaches to increase multicore efficiency, there is a greater need to devise multicore benchmarks that can be used to measure and compare both scalability and performance. These benchmarks should be easily portable so they can run on bare metal or on commonly available operating systems. Because of added sophistication and complexity, it is important to follow a modular approach such that complex workloads can be created using basic building blocks. At the lowest level, benchmarks should incorporate processing kernels that can be parameterized to vary computation versus memory access ratio. Representative algorithms from different application segments can be used to create some of these kernels.
Kernels should also be configurable so they can run on different cores in parallel with varying levels of resource contention. Combinations of these kernels can then be weaved together into complicated workload topologies that simulate various application-specific scenarios. As the industry and multicore applications evolve, more workloads can be designed and added to the repertoire of existing benchmarks. The output of these benchmarks should be an easy-to-compare score that reflects the time taken to complete a given workload on a particular number of cores.
There is no doubt that multicore processors enable new capabilities and provide tremendous improvements to performance, power consumption, and cost in existing embedded products. This market maintains excitement and promise, as reflected by the articles in this issue of Embedded Computing Design. It is fascinating to observe that while there are partial multicore benchmarking mechanisms leveraged in the industry, there is no mainstream, market-accepted multicore benchmarking strategy in place, especially in such cost-conscious economic times. Engineers and managers are often left with the arduous task of implementing their own time-consuming benchmarking efforts on several devices before making their final selection.
It is hard not to ask why this is the case with such bright and innovative engineers in the multicore market. Perhaps this special edition featuring multicore will serve as a call to action to establish a viable, market-accepted multicore benchmarking strategy that benefits not only the embedded engineers using such devices, but multicore SoC manufacturers as well.
Texas Instruments [email protected] www.ti.com
Follow: Twitter Facebook Google+ LinkedIn YouTube




