
Getting the most from multicore silicon with embedded virtualization
May 01, 2010
Story

Embedded virtualization offers a scalable mechanism for realizing the benefits of multicore processing power.
Virtualization in embedded applications has much in common with its enterprise and desktop equivalents. Unique embedded use cases and specialized underlying technology offer developers new opportunities to optimize designs for performance and responsiveness.
Adoption of multicore technology on the desktop, in the data center, and now in embedded designs responds to comparable needs – scaling compute capacity without stepping up system clocks and attaining more MIPS per watt for next-generation devices and applications.
Mainstream multicore on the desktop and in data centers requires Symmetric Multi-Processing (SMP) support from deployed Operating Systems (OSs). The Linux kernel has supported SMP for almost a decade, and SMP-capable Windows and Mac OS versions are widely used today.
By contrast, embedded OSs are trying to catch up to support multicore CPUs. Even as OSs become more adept at running in multicore environments, applications and middleware still face the challenges of thread safety, concurrency, and load balancing.
Virtualization software architectures
To solve these challenges, different virtualization strategies have emerged, starting with Type I and Type II, as shown in Figure 1. In Type I virtualization, the hypervisor “owns” the CPU and is responsible for booting and running guest OSes. Type I platforms are “lean, and mean,” and mature, emerging from generations of development for mainframes and minis, and now for mobile devices. By contrast, Type II virtualization offered by platforms such as VMware Fusion, Parallels, and Sun VirtualBox focuses on end-user experience, with the hypervisor running as an application over another OS with no performance guarantees.
|
|

Embedded virtualization follows its own paradigms. In infrastructure applications like routers, switches, and gateways, use cases resemble the enterprise. Type I hypervisors host instances of Linux or a Real-Time OS (RTOS) to support virtual appliances (firewalls, deep-packet inspectors, and other appliances) on a single piece of hardware or virtual spares in a redundant high-availability architecture.
In mobile devices, OEMs use bare-metal virtualization to consolidate multiple CPUs to run baseband, multimedia, and application stacks and diverse OSs (Android or Linux in one or more virtual machines, and an RTOS in another) on a single CPU to save bill-of-material costs.
Going for multicore
In addition to hardware consolidation, virtualization provides a good mechanism for distributing existing loads across multiple cores in a single processor. Embedded OS architects tend to see multicore silicon as a collection of discrete CPUs. Most legacy RTOS multicore support reflects this perspective, with requirements for unique copies of the OS and stacks running quasi-cooperatively on separate cores.
As RTOS suppliers begin to create multicore versions of their wares, they often use static mapping of loads to cores in multicore silicon. Some embedded virtualization platforms require static assignment of hypervisors and the loads they host and run (that is, one hypervisor per CPU core, as shown in Figure 2).
|
|

Static mapping of physical silicon to virtualized loads is inefficient and fails to deliver the advantages conferred by virtualization. A more effective approach is provisioning each guest OS with a virtual CPU that can map to a single CPU (one-to-one), share a CPU (many-to-one), or spread across multiple cores (one-to-many), as depicted in Figure 3.
|
|

Mapping loads to virtual CPUs to physical cores can be locked at integration or varied to balance loads, as demonstrated in the following applications.
Load balancing
Today’s networked devices – mobile phones, set-top boxes, in-vehicle systems, network appliances, and almost any type of intelligent device – are application platforms with loads as varied and complex as desktop computers, data center blades, and servers. Multicore CPUs promise high throughput and zippy response from modern embedded software, but predicting loading and core utilization outstrips the process of integrating software from varied sources, especially from app stores.
Virtualization gives developers and integrators additional tools for optimizing device performance. An embedded hypervisor can monitor the loads of guest OSs and host policy software to allocate CPU cycles and other resources accordingly.
Multicore power management
Multicore systems can present steep challenges to power-management schemes optimized for single-core systems. In particular, many multicore Systems-on-Chip (SoCs) have limits to the scope and capability of Dynamic Voltage and Frequency Scaling (DVFS):
· SoC subsystems and multicore CPUs usually share supply voltages, clocks, cache, and other resources, meaning DVFS applies to all cores.
· Scaling voltage on one SoC subsystem (when possible) can limit communication with other subsystems over local buses and deny access to shared memory, including the subsystem’s own DRAM.
· Clock scaling of single SoC subsystems limits interoperability, especially for synchronous buses.
· Some operations use cores at full throttle or not at all, but others impose varying loads. All-or-nothing use is easy to manage, but dynamic loads on multiple cores present much greater power-management challenges.
Now add multiple OSs. High-level OSs typically include DVFS power management such as Linux Advanced Power Management and Dynamic Power Management as well as Windows/BIOS Advanced Configuration and Power Interface. Most RTOSs avoid operations that limit real-time responsiveness, and when they do offer explicit power-management APIs like vxLib’s vxPowerDown(), they lack power-management policies. Even if one OS is capable of managing power in its own domain, it will have no awareness of the capabilities and state of its peers in the same system.
DVFS delivers energy efficiency by reducing voltage and clock frequency. DVFS-enabled CPUs offer safe operating points at fixed voltages and frequencies. As load/demand increases or decreases, power-management middleware or OSs transition from operating point to operating point, as illustrated in Figure 4.
|
|
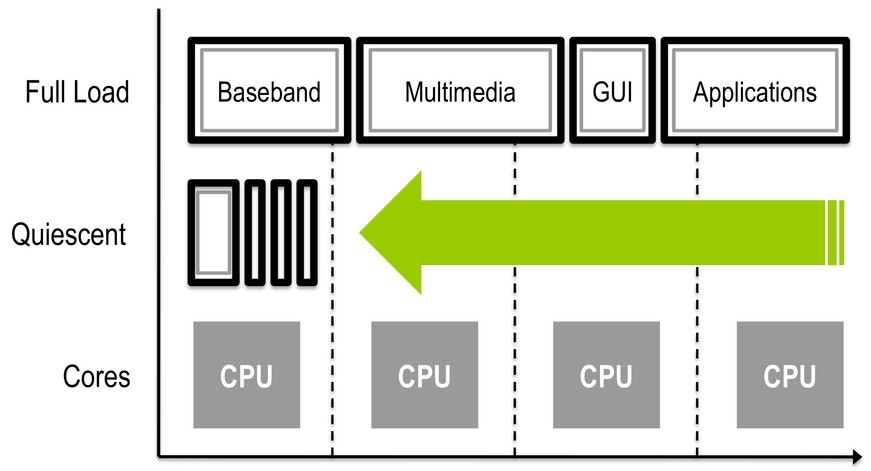
A logical extension of DVFS is reducing voltage to 0 VDC and stopping the CPU clock by utilizing only two operating points – full stop and full throttle – applied across the range of available cores. This neat trick is only possible with virtual CPUs (refer to Figures 3 and 4) for mapping loads to physical silicon and migrating running loads transparently across CPU cores. Shutting down whole cores is easier to manage than DVFS and leads to linear, highly predictable performance-energy trade-offs.
Multicore baseband
With the advent of high-bandwidth 4G networks, particularly LTE, mobile devices need to dedicate more processing power to wireless data communications. To enhance throughput with higher concurrency, emerging requirements call for dedicating entire cores to 4G I/O operations. This requirement has wireless chipset vendors and legacy RTOS suppliers scrambling to retool baseband OSs and software stacks for SMP operation.
The easier solution is to use mobile/embedded virtualization to enhance 4G throughput. Instead of dedicating two, four, or more cores to baseband processing, a hypervisor can map available cores to input or output operations as needed and scale back that mapping to support other CPU-intensive operations or perform per-core power management.
Only virtualization scales
Multicore software design is both more complex and simpler than meets the eye. System architects should resist the temptation to assign legacy software elements wholesale to available cores on next-generation embedded silicon.
Processor roadmaps point to further multiplication of available processor cores: today 2x on embedded CPUs, and soon 4x, 8x, and beyond. This surfeit of silicon will quickly outstrip static methods for provisioning and managing multicore software loads.
Only embedded/mobile virtualization can provide a scalable and flexible mechanism for realizing the benefits of multicore processing power and simplify system design, integration, and deployment, while making those systems more reliable and secure.
Rob McCammon is VP of product management for Open Kernel Labs (OK Labs). His prior experience includes marketing positions at Wind River, Integrated Systems, Software Development Systems, and Mentor Graphics/Microtec Research as well as engineering and technical sales roles at Hughes Electronics and HP. He holds a BS in Computer Engineering from the University of Illinois at Urbana-Champaign, an MS in Computer Engineering from the University of Southern California, and a Master’s of Management degree from Northwestern University.
OK Labs
312-924-1445
www.ok-labs.com



