
Video compression: Lost image resolution
July 27, 2017
Press Release

If your camera and recorder, storage, or displays are more than 500 feet apart, compression will likely be used to make it possible to transport the video.
Do you need 1080p video imagery? There are many parts needed to get there, including expensive new lenses, cameras, storage, and more. However, if you have compression such as H.264 or H.265 in the path, you’re not getting what you paid for. Here’s why.
HD recorders often use compression to reduce video clip file size to fit on small storage. If your camera (source) and recorder, storage, or displays (destination) are more than 500 feet apart, compression will likely be used to make it possible to transport the video. Indeed, compression compromises many aspects of the source image; resolution is another degrading effect.
MPEG H.264 and H.265 compression encoders analyze each image in a video sequence to create reference and differential frames to meet the bit rate limits of the transport or storage capacity the system is connected to. All frames are essentially divided into a mosaic of different-sized blocks. The block sizes depend on the detail content of the image in each mosaic area. Reference frames are divided up into macroblocks (Figure 1). Each macroblock consists of an array of image samples – luma (brightness) and chroma (color) – as delivered by the camera using the sampling system in use (e.g. 4:2:2). Block sizes are 8x8, 16x16, and 32x32. H.265 encoders can also merge adjoining macroblocks in large low detail areas. This tool contributes to the 50 percent compression efficiency of H.265. The criteria used by the encoder to determine block sizes and whether blocks can be merged are features of a particular encoder and are not controlled by any standard. This is in part why one can see image quality differences between encoders that meet H.264 and H.265 specification.

[Figure 1 | An image of a foreman divided into macroblocks]
However the image is divided into macroblocks, each block is passed through a discrete cosine transform (DCT). The DCT essentially converts the spacial contours of the macroblock into an array of two-dimensional (2D) frequencies (Figure 2). The upper left corner represents “DC” – that is, a contourless area of some brightness. The lower right corner represents the highest frequency contour that can be represented in the array. The DCT provides a coefficient to use when applying each element of this array to reconstruct the original contour of the macroblock. A zero value does not use the element. Coefficients can be any value, plus or minus, and is an output of the DCT.
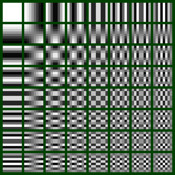
[Figure 2 | An example of a standard array used by a decoder.]
In a single dimension, this method is conceptually similar to how one transforms a time domain signal (waveform) to the frequency domain. Using the coefficients derived from a Fourier Transform of a square wave (both amplitude and phase), an array of prototype sinusoids can be added together to reconstruct the time domain wave form (Figure 3). Since the discrete transform is not a continuous spectrum, there is a quantization error built in to the reconstruction, whatever the size of the array (the one shown provides 256 elements to use in reconstructing the luma contour of an 8x8 pixel array).
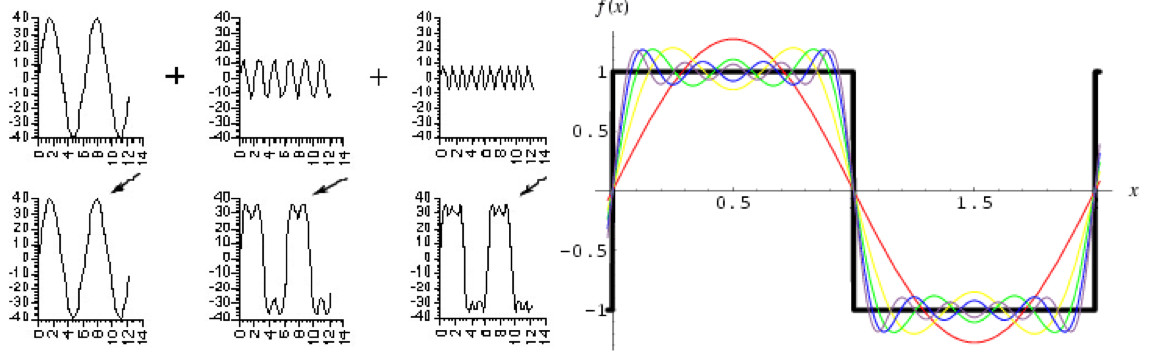
[Figure 3 | Using the coefficients derived from a Fourier Transform of a square wave, an array of prototype sinusoids can be added together to reconstruct the time domain wave form.]
The color samples (Cr and Cb) are processed the same way. Most cameras deliver 4:2:2 sampled imagery. The difficulty with that is the image sample is rectangular (two luma samples share one chroma sample) rather than square. To simplify the processing, most encoders will convert the incoming 4:2:2 sampling to 4:2:0 sampling where 4 luma samples share one chroma sample. In doing so, there is some detail loss and color shift. This can be observed when directly comparing the signals. Converting from 4:2:2 to 4:2:0 sampling effectively reduces the pixel bit depth from 20 bits to 15 bits. Digital image resolution is three dimensional, line count, pixels per line, and bit depth. Although the number of pixels per line and line count are unchanged, the bit depth is reduced, which has been shown to reduce fine image detail by limiting the dynamic range. That is, high contrast areas will suffer the most loss of detail.
The encoder (compressor) is also tasked with managing the output bit rate to ensure that the video and data streams can be reliably transported to its ultimate destination. One tool is to manage the macroblock size. Areas of an image, such as sky, will not have much contour and therefore many coefficients of the DCT will be at or near zero. The larger you can make such areas, the more zero coefficients there are. Long runs of zero coefficients compress well without data loss (entropy encoding phase). The more zero coefficients, the more entropy compression can be achieved.
Threshold |
Another tool available to the encoder is to adjust a value threshold where any DCT coefficients below an absolute magnitude of some value are set to zero. The strategy here is that decoding elements in the inverse DCT array that have small coefficients will introduce small errors in the resulting macroblock reconstructed contour. As the available transport bit rate is restricted, the encoder can increase the coefficient threshold, thus creating more zero values and thereby increasing the entropy phase compression ratio.
Figure 4 models a histogram of coefficients of an image in an 8x8 macroblock array (64 elements). Some coefficients are very small. The encoder can adjust the size of the threshold to eliminate elements of the array based on the value of the coefficient of the array. The elements are small contributors to the reconstruction of the macroblock contour. Of course, as this threshold is increased, so is the error between the source macroblock contour and the reconstructed contour. The effect is similar to the frequency to time domain reconstruction of the square wave shown earlier. That is, if a frequency is dropped out of the sum, ripples appear in the top of the square and the rise and fall slopes deviate from the original input.
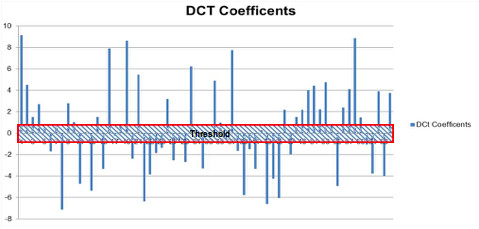
[Figure 4 |a histogram of coefficients of an image in an 8x8 macroblock array.]
The contour is different from macroblock to macroblock, so the effect varies with the contour. In macroblocks having complex contours, the effective bandwidth of the sampling is often reduced (zero coefficients). Visually this can shift a fine detail to fuzzy in the macroblock. To what level the threshold is set, however, is determined by the overall bit rate required to deliver the video and data stream. Therefore, the encoder will set the threshold based on what the aggregate bit rate of the stream of images deliver after the DCT phase. In any macroblock, the threshold may eliminate few if any array points; in others, it may eliminate many. In the sequence of images in Figure 5, the middle image is a reconstruction of the image at the far left. In this example, take note of the sheet music in the background. In this case, the threshold eliminated enough high frequency components in the macroblock array to support the transport bit rate that the detail on the sheet music was obliterated (compare areas circled in red). This information is lost forever after the compression is complete.

[Figure 5 | In any macroblock, the threshold may eliminate few if any array points; in others, it may eliminate many.]
As the macroblock size is increased, the complexity of the contour to recreate the sheet music increases. However, these elements create smaller DCT coefficients compared to the DC level and shading of the paper on which it is printed. The only way to prevent this information loss is to reduce the size of the macroblock at the target distance to reduce the complexity of the contour. This can be accomplished by reducing the size of the macroblock itself (32x32 to 16x16 or 8x8) or increasing the magnification. Increasing the magnification has the effect of reducing the target area a macroblock covers in the image.
An 8x8 array representing 64 raw video pixels is replaced by the DCT coefficients filtered by the threshold. The MPEG standards define how this information is communicated to a decoder. The decoder now only has the filtered data to perform and inverse DCT to recreate the pixel array contour. The decoded image is a mosaic of these recreated contours (macroblocks) sewn together. Here, an algorithm can be applied to the decoded mosaic to hide the seams. This algorithm is not standardized and is often a differentiator for a decoder supplier relating to subjective image quality.
In Figure 5, from left to right is the original image, the decoded image recreated from a mosaic of gradient macroblocks, and the same mosaic after deblocking where the edges of the mosaic elements are smudged out.
In addition to the lost detail, regions around the macroblocks are smudged to hide the boundaries. This process further modifies the original image data. The modifications are permanent when captured as single images. The smudge itself may be different from decoder to decoder and cause fine detail differences from station to station, image capture to image capture.
How do you relate all of this to resolution loss? When the higher frequency elements of the inverse DCT array are removed, edge details become fuzzy. The fuzziness can be thought of as progressively defocusing the lenses as high frequency elements are removed to meet bit rate limitations.
However, what detail is compromised? Is it significant? The answer to that is a matter of scale. In a 1080x1920 image we know the percentage a 16x16 macroblock of pixels takes up on the image frame, but more important is what the complexity of the contour of the macroblock is. The complexity is determined in large part by what is in the image area of the macroblock at the target range.
To exemplify the scale impact, Figure 6 simulates the macroblock area at the target where the lens zoom position would affect what detail is in the macroblock area. At the left represents an arbitrary lens setting. The image at the right represents looking at the same area with a narrower field of view (FOV). As you can see the complexity of the highlighted macroblock (red) in the left image is far greater than the complexity of the same macroblock where the FOV is smaller. In the left image, increases in threshold will wash out the details around the man’s eye. In the image to the right, the contour of the same macroblock is less complicated. It will produce fewer significant coefficients after the DCT is completed, therefore preserving most of the detail during decode.

[Figure 6 | Lens zoom position affects what detail is in the macroblock area.]
What is the resolution loss? The answer is complicated: it is image dependent, macroblock scale dependent, and bit rate dependent. What detail is effected depends also on what is in the macroblock. Having said that, one can relate it to macroblock size and available bit rate and storage capacity the lower the available bit rate, the smaller the macroblock area must represent at the target image to preserve the same or nearly the same detail delivered by the raw pixels from the source.
Requiring more zoom and better optics to deliver an image with similar detail on the decoder side translates to image resolution loss in the process. The resolution loss is not recoverable as the 2D elements created by the DCT on the encode side, zeroed to meet the bit rate limits, are lost forever during the encoding process.
Let us suppose a 1080p camera is being used to view an object 500 feet away. If a 1000 mm lens is used with a 25 mm sensor, the FOV would approximately be 1.5 degrees. The horizontal distance covered at the target range would be about 160 inches (13 feet). Each pixel at this range would cover 0.08 inches or approximately 0.007 inches2. The 8x8 macroblock covers about 0.43 inches2. What is the complexity of the image of a 0.007 inch2 are vs a 0.43 inch2 image area? Clearly the smaller the area covered by the macroblock the lower the detail loss. Conversely, to compensate for compression encoder detail loss, the lower the bit rate, the greater the magnification needed. In specifying systems where compression is in the delivery path of the video, requirements must consider these effects. If the devil is in the details, the details are important. Full resolution single frame shots are an integral part of analysis or evidence retention. With recent innovations in Video Recording Instruments (VRI) it is now possible to capture uncompressed HD-SDI video, with zero color shift, quantization errors, or DCT coefficient losses.



