Taking the Top off TOPS in Inferencing Engines
January 30, 2019
Story

With the explosive growth of AI, there has become an intense focus on new specialized inferencing engines that can deliver the performance that AI demands.
With the explosive growth of AI, there has become an intense focus on new specialized inferencing engines that can deliver the performance that AI demands. As a result, we’ve seen a continual array of neural inferencing hardware announcements over the last six months, all promising to deliver better acceleration than anything else on the market. However, the challenge is no one really knows how to measure one from another. This is a new technology and like any new technology, we need metrics and we need ones that really matter.
It’s All About Throughput
When the performance of inferencing engines come up, vendors throw out benchmarks citing things such as TOPS (Tera-Operations/Second) performance and TOPS/Watt. System/chip designers looking into these soon realize that these figures are generally meaningless. What really matters is what throughput an inferencing engine can deliver for a model, image size, batch size and process and PVT (process/voltage/temperature) conditions. This is the number one measurement of how well it will perform, but amazingly very few vendors provide it.
The biggest problem with TOPS is that when a company says their engine does X TOPS, they typically quote this without stating what the conditions are. Without knowing this information, they erroneously believe that an X TOPS means it can perform X trillion operations. In reality, a company quoting 130 TOPS may only deliver 27 TOPS of useable throughput.
Another benchmark being used, but less commonly, is ResNet-50. The problem with this benchmark is that most companies quoting it don’t give batch size. When they don’t give this, a chip designer can assume it will be a large batch size that maximizes their hardware utilization percentage. This makes ResNet-50 not very helpful as a benchmark. In contrast, YOLOv3 for example requires 100 times more operations to process a 2 Megapixel image. Hardware utilization will be even more challenged on “real world” models.
How to Properly Measure Neural Inferencing Engines
There are several key things to look at when evaluating neural inferencing engines. Below are the top considerations and why they really matter.
- Define what an operation is: Some vendors count a multiply (typically INT 8 times INT 8) as one operation and an accumulation (addition, typically INT 32) as one operation. Thus, a single multiply-accumulate equals 2 operations. However, some vendors include other types of operations in their TOPS specification so that must be clarified in the beginning.
- Ask what the operating conditions are: If a vendor gives TOPS without providing the conditions, they are often using room temperature, nominal voltage and typical process. Usually they will mention which process node they are referring to, but operating speeds differ between different vendors, and most processes are offered with 2, 3 or more nominal voltage. Since performance is a function of frequency, and frequency is a function of voltage, a chip designer can get more than twice the performance at 0.9V than at 0.6V. Frequency varies depending on the conditions/assumptions. Refer to this application note for more information on this.
- Look at batch size: Even if a vendor provides worst-case TOPS, chip designers need to figure out if all of those operations actually contribute to computing their neural network model. In reality, the actual utilization can be very low because no inferencing engine has 100 percent utilization of all of the MACs all of the time. That is why batch size matters. Batching is where weights are loaded for a given layer and process multiple data sets at the same time. The reason to do this is to improve throughput, but the give-up is longer latency. ResNet-50 has over 20 million weights; YOLOv3 has over 60 million weights; and every weight must be fetched and loaded into the MAC structure for every image. There are too many weights to keep them all resident in the MAC structure.
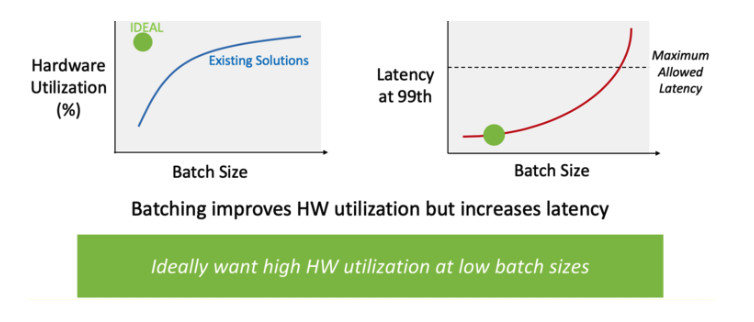
- Finding your MAC utilization: Not all neural networks behave the same. You need to find out the actual MAC utilization for the neural inference engine for the neural network model you want to deploy, at the batch size you require.
Getting to the Bottom of TOPS
If you are a designer looking at neural inferencing engines, hopefully this article sheds some light on what to look for. Just remember – it’s throughput that matters. It’s important not to get caught up in meaningless benchmarks such as TOPS and ResNet-50 unless you know the things to ask around those. Start by asking questions such as: how many images/seconds can be processed for a particular model, say YOLOv3, at batch size = A & at XYZ PVT conditions. Once you start specifying the conditions and assumptions, you will start to get an understanding of how well any neural inferencing will perform in the real world. At the end of the day, that is what matters most.
Geoff Tate is CEO and co-founder of Flex Logix, Inc. Earlier in his career, he was the founding CEO of Rambus where he and 2 PhD co-founders grew the company from 4 people to an IPO and a $2 billion market cap by 2005. Prior to Rambus, Mr. Tate worked for more than a decade at AMD where he was Senior VP, Microprocessors and Logic with more than 500 direct reports.
Prior to joining Flex Logix, Mr. Tate ran a solar company and served on several high tech boards. He currently is a board member of Everspin, the leading MRAM company.
Mr. Tate is originally from Edmonton, Canada and holds a Bachelor of Science in Computer Science from the University of Alberta and an MBA from Harvard University. He also completed his MSEE (coursework) at Santa Clara University.